Archive for the ‘Cloud computing’ Category
Introduction to Policy as Code

Building our first environment in the cloud, or perhaps migrating our first couple of workloads to the cloud is fairly easy until we begin the ongoing maintenance of the environment.
Pretty soon we start to realize we are losing control over our environment – from configuration changes, forgetting to implement security best practices, and more.
At this stage, we wish we could have gone back, rebuilt everything from scratch, and have much more strict rules for creating new resources and their configuration.
Manual configuration simply doesn’t scale.
Developers would like to focus on what they do best – developing new products or features, while security teams would like to enforce guard rails, allowing developers to do their work, while still enforcing security best practices.
In the past couple of years, one of the hottest topics is called Infrastructure as Code, a declarative way to deploy new environments using code (mostly JSON or YAML format).
Infrastructure as Code is a good solution for deploying a new environment or even reusing some of the code to deploy several environments, however, it is meant for a specific task.
What happens when we would like to set guard rails on an entire cloud account or even on our entire cloud organization environment, containing multiple accounts, which may expand or change daily?
This is where Policy as Code comes into the picture.
Policy as Code allows you to write high-level rules and assign them to an entire cloud environment, to be effective on any existing or new product or service we deploy or consume.
Policy as Code allows security teams to define security, governance, and compliance policies according to business needs and assign them at the organizational level.
The easiest way to explain it is – can user X perform action Y on resource Z?
A more practical example from the AWS realm – block the ability to create a public S3 bucket. Once the policy was set and assigned, security teams won’t need to worry whether or not someone made a mistake and left a publicly accessible S3 bucket – the policy will simply block this action.
Looking for a code example to achieve the above goal? See:
https://aws-samples.github.io/aws-iam-permissions-guardrails/guardrails/scp-guardrails.html#scp-s3-1
Policy as Code on AWS
When designing a multi-account environment based on the AWS platform, you should use AWS Control Tower.
The AWS Control Tower is aim to assist organizations deploying multiple AWS accounts under the same AWS organization, with the ability to deploy policies (or Service Control Policies) from a central location, allowing you to have the same policies for every newly created AWS account.
Example of governance policy:
- Enabling resource creation in a specific region – this capability will allow European customers to restrict resource creation in regions outside Europe, to comply with the GDPR.
- Allow only specific EC2 instance types (to preserve cost).
Example of security policies:
- Prevent upload of unencrypted objects to S3 bucket, to protect access to sensitive objects.
https://aws-samples.github.io/aws-iam-permissions-guardrails/guardrails/scp-guardrails.html#scp-s3-2
- Deny the use of the Root user account (least privilege best practice).
AWS Control Tower allows you to configure baseline policies using CloudFormation templates, over an entire AWS organization, or on a specific AWS account.
To further assist in writing CloudFormation templates and service control policies on large scale, AWS offers some additional tools:
Customizations for AWS Control Tower (CfCT) – ability to customize AWS accounts and OU’s, make sure governance and security policies remain synched with security best practices.
AWS CloudFormation Guard – ability to check for CloudFormation templates compliance against pre-defined policies.
Summary
Policy as Code allows an organization to automate governance and security policies deployment on large scale, keeping AWS organizations and accounts secure, while allowing developers to invest time in developing new products, with minimal required changes to their code, to be compliant with organizational policies.
References
- Best Practices for AWS Organizations Service Control Policies in a Multi-Account Environment
- AWS IAM Permissions Guardrails
https://aws-samples.github.io/aws-iam-permissions-guardrails/guardrails/scp-guardrails.html
- AWS Organizations – general examples
- Customizations for AWS Control Tower (CfCT) overview
https://docs.aws.amazon.com/controltower/latest/userguide/cfct-overview.html
- Policy-as-Code for Securing AWS and Third-Party Resource Types
https://aws.amazon.com/blogs/mt/policy-as-code-for-securing-aws-and-third-party-resource-types/
Journey for writing my first book about cloud security

My name is Eyal, and I am a cloud architect.
I have been in the IT industry since 1998 and began working with public clouds in 2015.
Over the years I have gained hands-on experience working on the infrastructure side of AWS, Azure, and GCP.
The more I worked with the various services from the three major cloud providers, the more I had the urge to compare the cloud providers’ capabilities, and I have shared several blog posts comparing the services.
In 2021 I was approached by PACKT publishing after they came across one of my blog posts on social media, and they offered me the opportunity to write a book about cloud security, comparing AWS, Azure, and GCP services and capabilities.
Over the years I have published many blog posts through social media and public websites, but this was my first experience writing an entire book with the support and assistance of a well-known publisher.
As with any previous article, I began by writing down each chapter title and main headlines for each chapter.
Once the chapters were approved, I moved on to write the actual chapters.
For each chapter, I first wrote down the headlines and then began filling them with content.
Before writing each chapter, I have done research on the subject, collected references from the vendors’ documentation, and looked for security best practices.
Once I have completed a chapter, I submitted it for review by the PACKT team.
PACKT team, together with external reviewers, sent me their input, things to change, additional material to add, request for relevant diagrams, and more.
Since copyright and plagiarism are important topics to take care of while writing a book, I have prepared my diagrams and submitted them to PACKT.
Finally, after a lot of review and corrections, which took almost a year, the book draft was submitted to another external reviewer and once comments were fixed, the work on the book (at least from my side as an author) was completed.
From my perspective, the book is unique by the fact that it does not focus on a single public cloud provider, but it constantly compares between the three major cloud providers.
From a reader’s point of view or someone who only works with a single cloud provider, I recommend focusing on the relevant topics according to the target cloud provider.
For each topic, I made a list of best practices, which can also be referenced as a checklist for securing the cloud providers’ environment, and for each recommendation I have added reference for further reading from the vendors’ documentation.
If you are interested in learning how to secure cloud environments based on AWS, Azure, or GCP, my book is available for purchase in one of the following book stores:
- Amazon:
https://www.amazon.com/Cloud-Security-Handbook-effectively-environments/dp/180056919X
- Barnes & Noble:
https://www.barnesandnoble.com/w/cloud-security-handbook-eyal-estrin/1141215482?ean=9781800569195
- PACKT
https://www.packtpub.com/product/cloud-security-handbook/9781800569195
Introduction to cloud financial management on AWS

Cloud financial management (sometimes also referred to as FinOps) is about managing the ongoing cost of cloud services.
Who should care about cloud financial management? Basically, anyone consuming IaaS or PaaS services – from IT, DevOps, developers, architects and naturally finance department.
When we start consume IaaS or PaaS services, we realized that almost any service has its pricing model – we just need to read the service documentation.
Some of the services’ pricing model are easy to understand, such as EC2 (you pay for the amount of time and EC2 instance was up and running), and some of services’ pricing model can be harder to calculate (you pay for the number of times the function was called in a month and the amount of memory allocated to the function).
In this post, we will review the tools that AWS offer us to manage cost.
Step 1 – Cost management for beginners
The first thing that AWS recommend for new customers is to use Amazon CloudWatch to create billing alarms.
Even if you cannot estimate your monthly cost, create a billing alarm (for example – send me email whenever the charges are above 200$). When time goes by, you will be able to adjust the value, per your account usage pattern.
To read more information about billing alarms, see:
If you already know that certain department is using specific AWS account and has a known budget, use AWS budgets, to create a monthly, quarterly or even yearly budget, and configure the budget interface to send you notifications whenever the amount of money consumed is about certain threshold of your pre-defined budget.
To read more about AWS budget creation, see:
https://docs.aws.amazon.com/cost-management/latest/userguide/budgets-create.html
If you wish to visualize your resource consumption over period of time, see trends, generate reports and customize the resource consumption information, use AWS Cost Explorer.
To read more about AWS Cost Explorer, see:
https://docs.aws.amazon.com/cost-management/latest/userguide/ce-what-is.html
Finally, if you wish to receive recommendations about saving costs, you have an easy tool called AWS Trusted Advisor.
The tool helps you get recommendations about cost optimization, performance, security and more.
This tool is the easiest way to get insights about how to save cost on AWS platform.
To read more about AWS Trusted Advisor, see:
https://aws.amazon.com/premiumsupport/knowledge-center/trusted-advisor-cost-optimization
Step 2 – Resource tagging and rightsizing
One of the best ways to detect and monitor cost over time and per business case (project, division, environment, etc.) is to use tagging.
You add descriptive tag for each and every resource you create, that will allow you later on to know which resources has been consumed – for example, which EC2 instances, public IP’s, S3 buckets and RDS instances, all relate to the same project.
For more information about AWS cost allocation tags, see:
https://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/cost-alloc-tags.html
If you manage multiple AWS accounts, all relate to the same AWS organization, it is considered best practice to configure all account costs in a single place, also known as consolidated billing.
You will define which AWS account will store billing information, and redirect all AWS accounts in your organization to this central account.
Using consolidated billing, will allow you to achieve volume discount, for example – volume discount for the total data transferred from multiple AWS accounts to the Internet, instead of separate charge per AWS account.
For more information about consolidated billing, see:
https://docs.aws.amazon.com/awsaccountbilling/latest/aboutv2/consolidated-billing.html
By using compute services such as Amazon EC2 or Amazon RDS, you might be wasting money, by not using the right size (amount of memory/CPU) per your actual resource demand (for example – paying on large instance, when it is underutilized).
Tools such as AWS Trusted Advisor mentioned earlier, will help you get insights and recommend you to change instance size, to save money.
Another tool that can assist you choose an optimal size for your instances is AWS Compute Optimizer, which scan your AWS environment and generate recommendations for optimizing your compute resources.
For more information about AWS Cost Optimizer, see:
https://docs.aws.amazon.com/compute-optimizer/latest/ug/getting-started.html
Even when using storage services such as Amazon S3, you can save money, by using the right storage class per actual use (for example Amazon S3 standard for big data analytics, Amazon S3 Glacier for archive, etc.)
There are two options for optimizing S3 cost:
- Using lifecycle policies, you configure how much time will an object stay in specific storage class without using the object, before it moves to a cheaper tier (until the object finally moves into deep archive tier or even deleted completely).
For more information about setting lifecycle policies, see:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/how-to-set-lifecycle-configuration-intro.html
- Using S3 Intelligent-Tiering, objects will automatically move to the most cost-effective storage tier by their access frequency. Unlike lifecycle policies, object might move between hot storage (such as S3) to archive storage (such as S3 Glacier or deep archive), and vice versa, if an object in an archive tier suddenly was accessed, it will move to hot tier (such as S3).
For more information about S3 Intelligent-tiering, see:
https://docs.aws.amazon.com/AmazonS3/latest/userguide/using-intelligent-tiering.html
Another simply tip for saving cost is to remove unused resources – from underutilized EC2 instance, unassigned public IP address, unattached EBS volume, etc.
AWS Trusted Advisor can assist you discover underutilized or unused resources.
For more information, see:
Step 3 – Get to know your workloads (cloud optimization)
When you deploy your workload for the first time, you don’t have enough information about its potential usage and cost.
You might choose too small or too large instance type, you might be using too expensive storage tier, etc.
One of the ways to save cost on development or test environments, which might not need to run over weekends or after working hours, is to use AWS Instance scheduler – a combination of tagging and Lambda function, which allow you to schedule instance (both EC2 and RDS) shutdown on pre-defined hours.
For more information about AWS instance scheduler, see:
https://aws.amazon.com/premiumsupport/knowledge-center/stop-start-instance-scheduler
If your workload can survive sudden shutdown and return to function from the moment it stopped (such as video rendering, HPC workloads for genomic sequencing, etc.) and you wish to save money, use AWS Spot instances, which allows you to save up to 90% of the cost, as compared to on-demand cost.
For more information about Spot instances, see:
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-spot-instances.html#spot-get-started
If your workload has the same usage pattern for long period of time (without shutdown or restart), consider one of the following options:
- Amazon EC2 Reserved Instances – allows you to reserve capacity for 1 or 3 years in advanced, and save up to 72% of the on-demand price.
For more information, see:
https://aws.amazon.com/ec2/pricing/reserved-instances/buyer
- Compute savings plans – commitment to use EC2 instances, regardless of instance family, size, AZ or region. Allows saving up 66% of on-demand price.
- EC2 instance saving plans – commitment to use specific instance family in specific region. Allows saving up to 72% of on-demand price.
For more information, see:
https://aws.amazon.com/savingsplans/faq/#Compute_.26_EC2_Instances_Savings_Plans
Summary
In this introduction post, we have reviewed the most common tools from AWS for detecting, managing and optimizing cost.
Using automated tools, allows organizations to optimize their resource consumption cost over time and over large scale and constant changing environments.
Not all cloud providers are built the same

When organizations debate workload migration to the cloud, they begin to realize the number of public cloud alternatives that exist, both U.S hyper-scale cloud providers and several small to medium European and Asian providers.
The more we study the differences between the cloud providers (both IaaS/PaaS and SaaS providers), we begin to realize that not all cloud providers are built the same.
How can we select a mature cloud provider from all the alternatives?
Transparency
Mature cloud providers will make sure you don’t have to look around their website, to locate their security compliance documents, allow you to download their security controls documentation, such as SOC 2 Type II, CSA Star, CSA Cloud Controls Matrix (CCM), etc.
What happens if we wish to evaluate the cloud provider by ourselves?
Will the cloud provider (no matter what cloud service model), allow me to conduct a security assessment (or even a penetration test), to check the effectiveness of his security controls?
Global presence
When evaluating cloud providers, ask yourself the following questions:
- Does the cloud provider have a local presence near my customers?
- Will I be able to deploy my application in multiple countries around the world?
- In case of an outage, will I be able to continue serving my customers from a different location with minimal effort?
Scale
Deploying an application for the first time, we might not think about it, but what happens in the peak scenario?
Will the cloud provider allow me to deploy hundreds or even thousands of VM’s (or even better, containers), in a short amount of time, for a short period, from the same location?
Will the cloud provider allow me infinite scale to store my data in cloud storage, without having to guess or estimate the storage size?
Multi-tenancy
As customers, we expect our cloud providers to offer us a fully private environment.
We never want to hear about “noisy neighbor” (where one customer is using a lot of resources, which eventually affect other customers), and we never want to hear a provider admits that some or all of the resources (from VMs, database, storage, etc.) are being shared among customers.
Will the cloud provider be able to offer me a commitment to a multi-tenant environment?
Stability
One of the major reasons for migrating to the cloud is the ability to re-architect our services, whether we are still using VMs based on IaaS, databases based on PaaS, or fully managed CRM services based on SaaS.
In all scenarios, we would like to have a stable service with zero downtime.
Will the cloud provider allow me to deploy a service in a redundant architecture, that will survive data center outage or infrastructure availability issues (from authentication services, to compute, storage, or even network infrastructure) and return to business with minimal customer effect?
APIs
In the modern cloud era, everything is based on API (Application programming interface).
Will the cloud provider offer me various APIs?
From deploying an entire production environment in minutes using Infrastructure as Code, to monitoring both performances of our services, cost, and security auditing – everything should be allowed using API, otherwise, it is simply not scale/mature/automated/standard and prone to human mistakes.
Data protection
Encrypting data at transit, using TLS 1.2 is a common standard, but what about encryption at rest?
Will the cloud provider allow me to encrypt a database, object storage, or a simple NFS storage using my encryption keys, inside a secure key management service?
Will the cloud provider allow me to automatically rotate my encryption keys?
What happens if I need to store secrets (credentials, access keys, API keys, etc.)? Will the cloud provider allow me to store my secrets in a secured, managed, and audited location?
In case you are about to store extremely sensitive data (from PII, credit card details, healthcare data, or even military secrets), will the cloud provider offer me a solution for confidential computing, where I can store sensitive data, even in memory (or in use)?
Well architected
A mature cloud provider has a vast amount of expertise to share knowledge with you, about how to build an architecture that will be secure, reliable, performance efficient, cost-optimized, and continually improve the processes you have built.
Will the cloud provider offer me rich documentation on how to achieve all the above-mentioned goals, to provide your customers the best experience?
Will the cloud provider offer me an automated solution for deploying an entire application stack within minutes from a large marketplace?
Cost management
The more we broaden our use of the IaaS / PaaS service, the more we realize that almost every service has its price tag.
We might not prepare for this in advance, but once we begin to receive the monthly bill, we begin to see that we pay a lot of money, sometimes for services we don’t need, or for an expensive tier of a specific service.
Unlike on-premise, most cloud providers offer us a way to lower the monthly bill or pay for what we consume.
Regarding cost management, ask yourself the following questions:
Will the cloud provider charge me for services when I am not consuming them?
Will the cloud provider offer me detailed reports that will allow me to find out what am I paying for?
Will the cloud provider offer me documents and best practices for saving costs?
Summary
Answering the above questions with your preferred cloud provider, will allow you to differentiate a mature cloud provider, from the rest of the alternatives, and to assure you that you have made the right choice selecting a cloud provider.
The answers will provide you with confidence, both when working with a single cloud provider, and when taking a step forward and working in a multi-cloud environment.
References
Security, Trust, Assurance, and Risk (STAR)
https://cloudsecurityalliance.org/star/
SOC 2 – SOC for Service Organizations: Trust Services Criteria
https://www.aicpa.org/interestareas/frc/assuranceadvisoryservices/aicpasoc2report.html
Confidential Computing and the Public Cloud
https://eyal-estrin.medium.com/confidential-computing-and-the-public-cloud-fa4de863df3
Confidential computing: an AWS perspective
https://aws.amazon.com/blogs/security/confidential-computing-an-aws-perspective/
AWS Well-Architected
https://aws.amazon.com/architecture/well-architected
Azure Well-Architected Framework
https://docs.microsoft.com/en-us/azure/architecture/framework/
Google Cloud’s Architecture Framework
https://cloud.google.com/architecture/framework
Oracle Architecture Center
https://docs.oracle.com/solutions/
Alibaba Cloud’s Well-Architectured Framework
Knowledge gap as a cloud security threat

According to Gartner survey, “Through 2022, traditional infrastructure and operations skills will be insufficient for 58% of the operational tasks”, combine this information with previous Gartner forecast that predicts that organizations’ spend on public cloud services will grow to 397 billion dollars, and you began to understand we have a serious threat.
Covid-19 and the cloud era
The past year and a half with the Covid pandemic forced organizations to re-evaluate their IT services and as a result, more and more organizations began shifting to work from anywhere and began migrating part of their critical business applications from their on-premise environments to the public cloud.
The shift to the public cloud was sometimes quick, and in many cases, without proper evaluation of the security risk to their customer’s data.
Where is my data?
Migrating to the public cloud began raising questions such as “where is my data located”?
The hyper-scale cloud providers (such as AWS, Azure, GCP) have a global presence around the world, but the first question we should always ask is “where is my data located” and should we build new environments in a specific country or continent to comply with data protection laws such as the GDPR in Europe, the CCPA in California, etc.
Hybrid cloud, multi-cloud, any cloud?
Almost any organization began using the public cloud hear about the terms “hybrid cloud” and “multi-cloud”, and began debating on future architecture suits to the organization needs and business goals.
I often hear the question – should I choose AWS, Azure, GCP, or perhaps a smaller public cloud provider, that will allow me to migrate to the cloud and be able to support my business needs?
Security misconfiguration
Building new environments in the public cloud, using “quick and dirty methods”, often comes with misconfigurations, from allowing public access to cloud storage services, to open access to databases containing customer’s data, etc.
Closing the knowledge gap
To prepare your organization for cloud adoption, the top management should invest a budget in employee training (from IT, support team, development teams, and naturally information security team).
The Internet is full of guidelines (from fundamental cloud services to security) and low-cost online courses.
Allow your employees to close the skills gap, invest time allowing your security teams to shift their mindset from the on-premise environments (and attack surface) to the public cloud.
Allow your security teams to take the full benefit of managed services and built-in security capabilities (from auditing, encryption, DDoS protection, etc.) that are embedded as part of mature cloud services.
Modern cloud deployment and usage
When migrating existing environments to the cloud, or even when building and deploying new environments in the cloud, there are many alternatives. There is no one right or wrong way.
In this post we will review the way it was done in the past (AKA “old school”) and review the more modern options for environment deployments.
Traditional deployment
Traditionally, when we had to deploy a new dev/test or a production environment for a new service or application, we usually considered 3 tier applications. These built from a presentation layer (such as web server or full client deployment), a business logic (such as application server) and a back-end storage tier (such as database server).
Since each layer (or tier) depended on the rest of the layers, each software upgrade or addition of another server (for high availability) required downtime for the entire application or service. The result: a monolith.
This process was cumbersome. It took several weeks to deploy the operating system, deploy the software, configure it, conduct tests, get approval from the business customer, take the same process to deploy a production environment and finally switch to production.
This process was viable for small scale deployments, or simple applications, serving a small number of customers.
We usually focus more on the system side of the deployment, perhaps a single server containing all the components. Until we reach the hardware limitations (CPU / Memory / Storage / Network limitations) before we begin to scale up (switching to newer hardware with more CPU / Memory / Storage / faster network interface card). Only then may we find out this solution does not scale enough to serve customers in the long run.
When replacing the VM size does not solve bottlenecks, we begin scale out by adding more servers (such as more web servers, cluster of database servers, etc.). Then we face new kind of problems, when we need to take the entire monolith down, every time we plan to deploy security patches, deploy software upgrades, etc.
Migrating existing architecture to the public cloud (AKA “lift and shift”) is a viable option, and it has its own pros and cons:
Pros:
· We keep our current deployment method
· Less knowledge is required from the IT team
· We shorten the time it takes to deploy new environments
· We will probably be able to keep our investment in licenses (AKA “Bring your own license”)
· We will probably be able to reuse our existing backup, monitoring and software deployment tools we used in the on-premises deployment.
Cons:
· Using the most common purchase model “on demand” or “pay as you go” is suitable for unknown usage patterns (such as development or test environment) but soon it will become expensive to use this purchase model on production environments, running 24×7 (even when using hourly based purchase model), as compared to purchase hardware for the on-premises, and using the hardware without a time limitation (until the hardware support ends)
· We are still in-charge of operating system maintenance (upgrades, backup, monitoring, various agent deployment, etc.) — the larger our server farm is, the bigger the burden we have on maintenance, until it does not scale enough, and we need larger IT departments, and we lower the value we bring to our organization.
Deployment in the modern world
Modern development and application deployment, also known as “Cloud Native applications”, focus on service (instead of servers with applications). It leverages the benefits of the cloud’s built-in capabilities and features:
Scale — We build our services to be able to serve millions of customers (instead of several hundred).
Elasticity — Our applications are aware of load and can expand or shrink resources in accordance with needs.
High availability — Instead of exposing a single server in a single data center to the Internet, we deploy our compute resources (VMs, containers, etc.) behind a managed load-balancer service, and we spread the server deployment between several availability zones (usually an availability zone equals a data center). This allows us to automatically monitor the server’s availability and deploy new compute resources when one server fails or when we need more compute resources due to server load. Since the cloud offers managed services (from load-balancers, NAT gateways, VPN tunnel, object storage, managed databases, etc.) we benefit from cloud providers’ SLAs, which are extremely difficult to get in traditional data centers.
Observability — In the past we used to monitor basic metrics such as CPU or memory load, free disk space (or maybe percentage of read/write events). Today, we add more and more metrics for the applications themselves, such as number of concurrent users, time it takes to query the database, percentage of errors in the web server log file, communication between components, etc. This allows us to predict service failures before our customers observe them.
Security — Managing and maintaining large fleets of servers in the traditional data center requires a huge amount of work (security patches, firewall rules, DDoS protection, configuration management, encryption at transit and at rest, auditing, etc.). In the cloud, we benefit from built-in security capabilities, all working together and accessible both manually (for small scale environments) and automatically (as part of Infrastructure as a Code tools and languages).
Containers and Kubernetes to the rescue
The use of microservice architecture revolutionized the way we develop and deploy modern applications by breaking previously complex architecture into smaller components and dividing them by the task they serve in our application or service.
This is where containers come into the picture. Instead of deploying virtual machines, with full operating system and entire software stacks, we use containers. This allows us to wrap the minimum number of binaries, libraries, and code, required for a specific task (login to the application, running the business logic, ingesting data into an object store or directly into the back-end database, running reporting model, etc.)
Containers enable better utilization of the existing “hardware” by deploying multiple containers (each can be for different service) on the same virtual hardware (or bare metal) and reach near 100% of resource utilization.
Containers allow small development teams to focus on specific tasks or components, almost separately from the rest of the development teams (components still needs to communicate between each other). They can upgrade lines of code, scale in and out according to load, and hopefully one day be able to switch between cloud providers (AKA be “Cloud agnostic”).
Kubernetes, is the de-facto orchestrator for running containers. It can deploy containers according to needs (such as load), monitor the status of each running container (and deploy a new container to replace of non-functioning container), automatically upgrade software build (by deploying containers that contain new versions of code), make certain containers are being deployed equally between virtual servers (for load and high availability), etc.
Pros:
· Decreases number of binaries and libraries, minimal for running the service
· Can be developed locally on a laptop, and run-in large scale in the cloud (solves the problem of “it runs on my machine”)
· Cloud vendor agnostic (unless you consume services from the cloud vendor’s ecosystem)
Cons:
· Takes time to learn how to wrap and maintain
· Challenging to debug
· A large percentage of containers available are outdated and contain security vulnerabilities.
Serverless / Function as a service
These are new modern ways to deploy applications in a more cost-effective manner, when we can take small portions of our code (AKA “functions”) for doing specific tasks and deploy them inside a managed compute environment (AKA “serverless”) and pay for the number of resources we consume (CPU / Memory) and the time (in seconds) it takes to run a function.
Serverless can be fitted inside microservice architecture by replacing tasks that we used to put inside containers.
Suitable for stateless functions (for example: no need to keep caching of data) or for scenarios where we have specific tasks. For example, when we need to invoke a function as result of an event, like closing a port in a security group, or because of an event triggered in a security monitoring service.
Pros:
· No need to maintain the underlying infrastructure (compute resources, OS, patching, etc.)
· Scales automatically according to load
· Extremely inexpensive in small scale (compared to a container)
Cons:
· Limited to maximum of 15 minutes of execution time
· Limited function storage size
· Challenging to debug due to the fact that it is a closed environment (no OS access)
· Might be expensive in large scale (compared to a container)
· Limited number of supported development languages
· Long function starts up time (“Warm up”)
Summary
The world of cloud deployment is changing. And this is good news.
Instead of server fleets and a focus on the infrastructure that might not be suitable or cost-effective for our applications, modern cloud deployment is focused on bringing value to our customers and to our organizations by shortening the time it takes to develop new capabilities (AKA “Time to market”). It allows us to experiment, make mistakes and recover quickly (AKA “fail safe”), while making better use of resources (pay for what we consume), being able to predict outages and downtime in advance.
Modern cloud virtualization
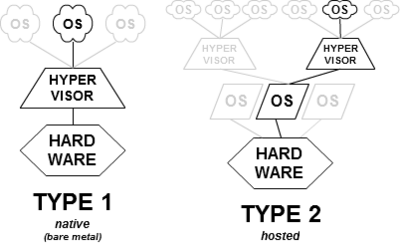
When we think about compute resources (AKA virtual machines) in the public cloud, most of us have the same picture in our head – operating system, above hypervisor, deployed above physical hardware.
Most public cloud providers build their infrastructure based on the same architecture.
In this post we will review traditional virtualization, and then explain the benefits of modern cloud virtualization.
Introduction to hypervisors and virtualization technology
The idea behind virtualization is the ability to deploy multiple operating systems, on the same physical hardware, and still allow each operating system access to the CPU, memory, storage, and network resources.
To allow the virtual operating systems (AKA “Guest machines”) access to the physical resources, we use a component called a “hypervisor”.
There are two types of hypervisors:
- Type 1 hypervisor – an operating system deployed on physical hardware (“bare metal” machine) and allows guest machines access to the hardware resources.
- Type 2 hypervisor – software within an operating system (AKA “Host operating system”) deployed on physical hardware. The guest machines are installed above the host operating system. The host operating system hypervisor allows guest machines access to the underlying physical resources.
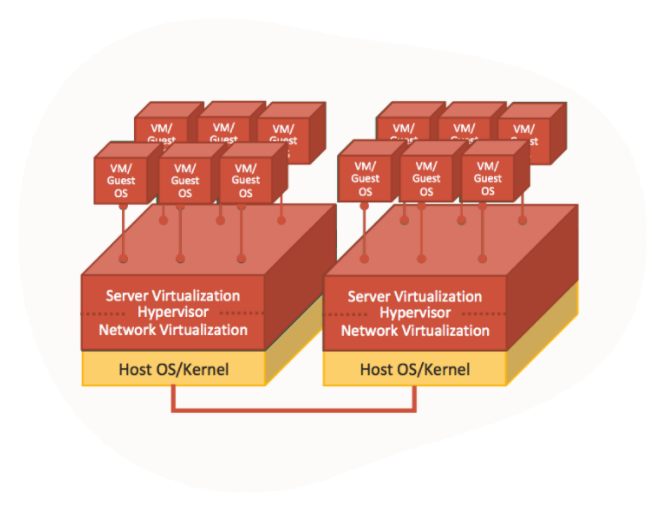
The main drawbacks of current hypervisors:
- There is no full isolation between multiple guest VMs deployed on the same hypervisor and the same host machine. All the network passes through the same physical NIC and same hypervisor network virtualization.
- The more layers we add (either type 1 or type 2 hypervisors), we increase overhead on the host operating system and host hypervisor. This means the guest VMs will not be able to take full advantage of the underlying hardware.
AWS Nitro System
In 2017 AWS introduced their latest generation of hypervisors.
The Nitro architecture, underneath the EC2 instances, made a dramatic change to the way we use hypervisors by offloading virtualization functions (such as network, storage, security, etc.) to dedicated software and hardware chips. This allows the customer to get much better performance, with much better security and isolation of customers’ data. Hypervisor prior to AWS Nitro:
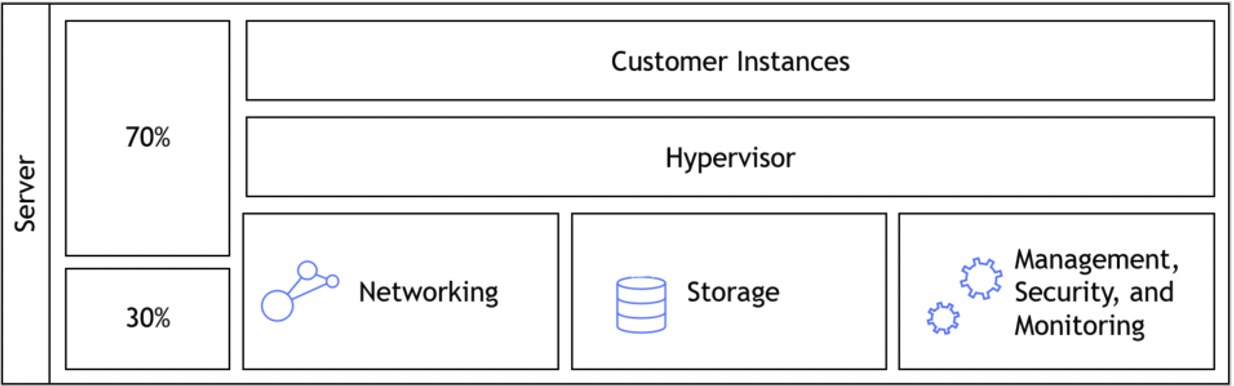
Hypervisor based on AWS Nitro:
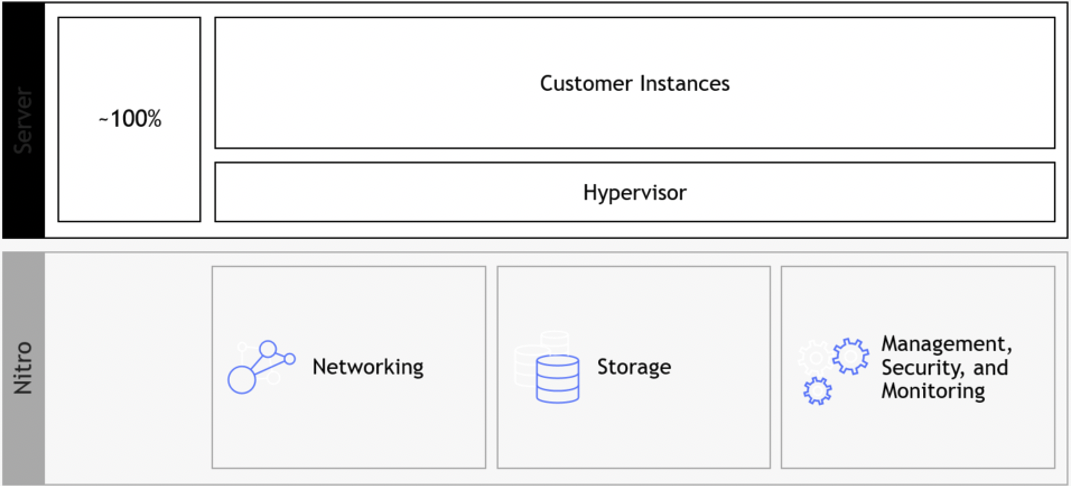
The Nitro architecture is based on Nitro cards:
- Nitro card for VPC – handles network connectivity to the customer’s VPC, and fast network connectivity using ENA (Elastic Network Adapter) controller
- Nitro card for EBS – allows access to the Elastic Block Storage service
- Nitro card for instance storage – allows access to the local disk storage
- Nitro security chip – provides hardware-based root of trust
In 2020, AWS introduced AWS Nitro Enclaves that allow customers to create isolated environments to protect customers’ sensitive data and reduce the attack surface.
EC2 instance prior to AWS Nitro Enclaves:
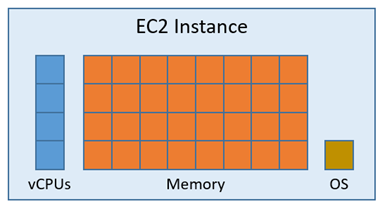
EC2 instance with AWS Nitro Enclaves enabled:
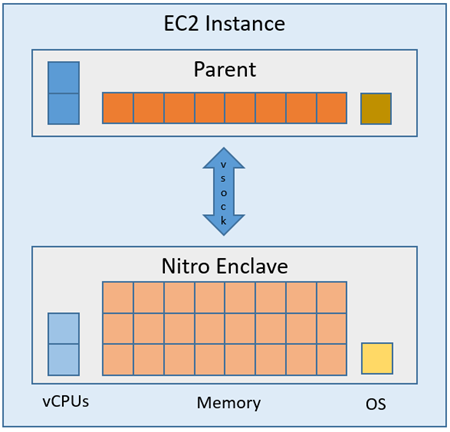
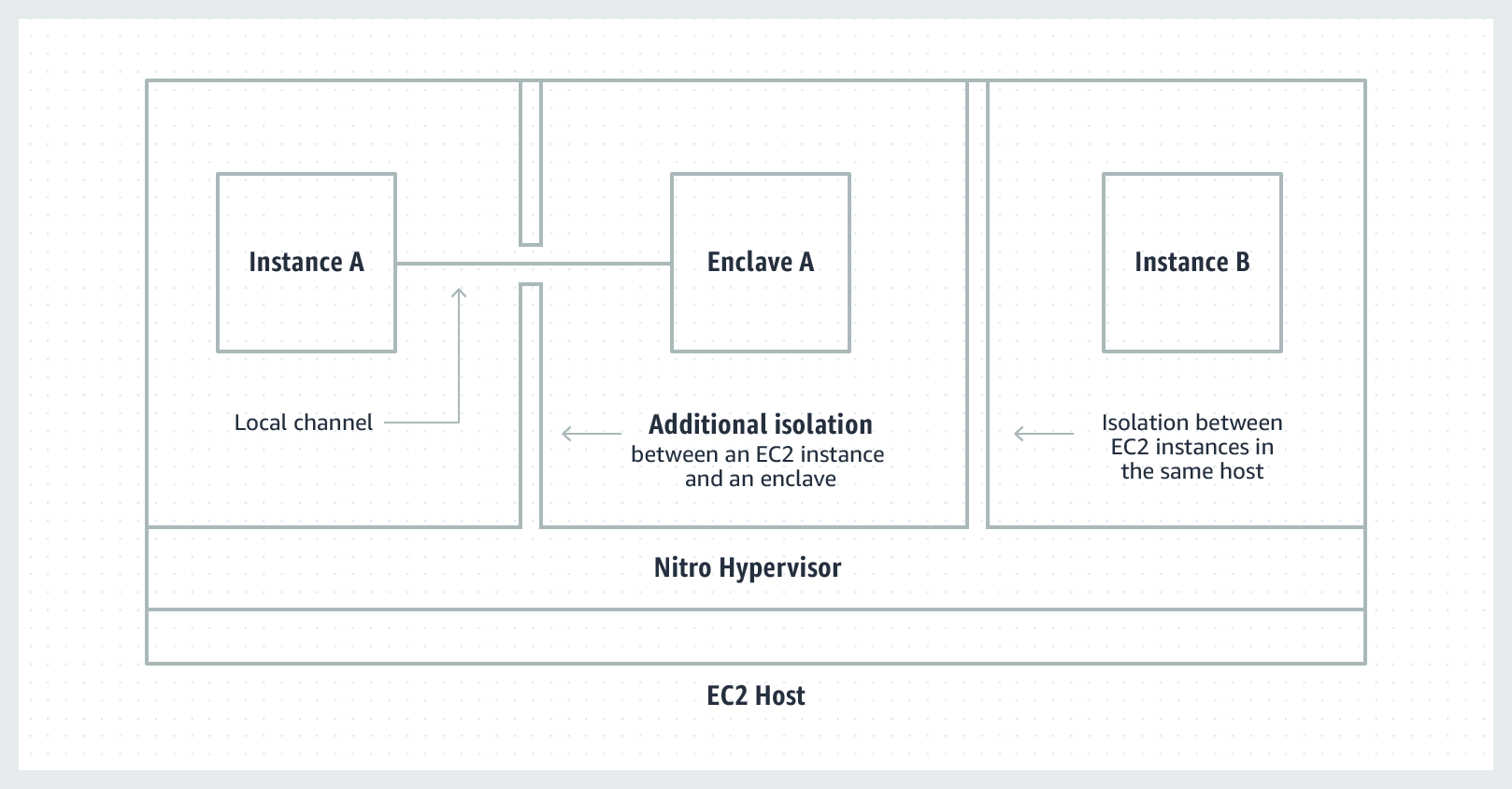
The diagram below shows two EC2 instances on the same EC2 host. One of the EC2 instances has Nitro Enclaves enabled:
Additional references:
- AWS Nitro System
https://aws.amazon.com/ec2/nitro/
- Reinventing virtualization with the AWS Nitro System
https://www.allthingsdistributed.com/2020/09/reinventing-virtualization-with-aws-nitro.html
- AWS Nitro – What Are AWS Nitro Instances, and Why Use Them?
https://www.metricly.com/aws-nitro/
- AWS Nitro Enclaves
https://aws.amazon.com/ec2/nitro/nitro-enclaves
- AWS Nitro Enclaves – Isolated EC2 Environments to Process Confidential Data
Oracle’s Generation 2 (GEN2) Cloud Infrastructure
In 2018 Oracle introduced their second generation of cloud infrastructures.
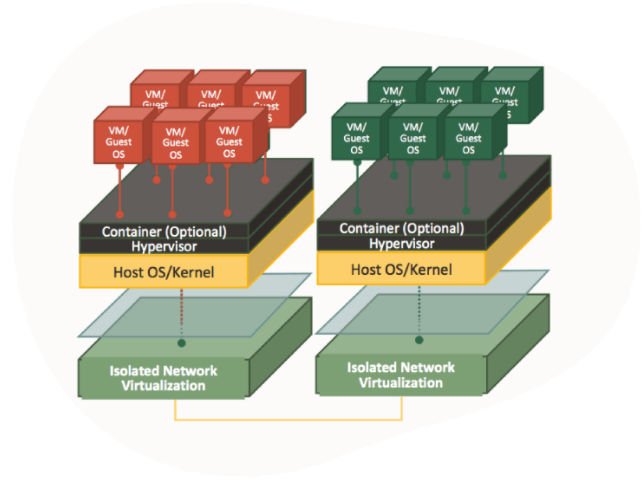
Oracle’s Gen2 cloud offers isolated network virtualization, using custom-designed SmartNIC (a special software and hardware card) which offers customers the following advantages:
- Reduced attack surface
- Prevent lateral traversal between bare-metal, container or VM hosts
- Protection against Man-in-the-Middle attacks between hosts and guest VMs
- Protection against denial-of-service attacks against VM instances
First generation cloud hypervisors:
Oracle Second generation cloud hypervisor:
Oracle Cloud architecture differs from the rest of the public cloud providers in terms of CPU power.
In OCI, 1 OCPU (Oracle Compute Unit) = 1 physical core, while other cloud providers use Intel hyperthreading technology, which calculates 2 vCPU = 1 physical core.
As a result, customers get better performance per each OCPU it consumes.
Another characteristic that differentiates OCI architecture is no resource oversubscription, which means a customer will never share the same resource (CPU, memory, network) with another customer. This avoids a “noisy neighbor” scenario and allows the customer better and guaranteed performance.
Additional references:
- Oracle Cloud Infrastructure Security Architecture
https://www.oracle.com/a/ocom/docs/oracle-cloud-infrastructure-security-architecture.pdf
- Oracle Cloud Infrastructure — Isolated Network Virtualization
https://www.oracle.com/security/cloud-security/isolated-network-virtualization/
- What is a Gen 2 Cloud?
https://blogs.oracle.com/platformleader/what-is-a-gen-2-cloud
- Exploring Oracle’s Gen 2 Cloud Infrastructure Security Architectures: Isolated Network Virtualization
- Properly sizing workloads in the Oracle Government Cloud: Save costs and gain performance with OCPUs
The Future of Data Security Lies in the Cloud

We have recently read a lot of posts about the SolarWinds hack, a vulnerability in a popular monitoring software used by many organizations around the world.
This is a good example of supply chain attack, which can happen to any organization.
We have seen similar scenarios over the past decade, from the Heartbleed bug, Meltdown and Spectre, Apache Struts, and more.
Organizations all around the world were affected by the SolarWinds hack, including the cybersecurity company FireEye, and Microsoft.
Events like these make organizations rethink their cybersecurity and data protection strategies and ask important questions.
Recent changes in the European data protection laws and regulations (such as Schrems II) are trying to limit data transfer between Europe and the US.
Should such security breaches occur? Absolutely not.
Should we live with the fact that such large organization been breached? Absolutely not!
Should organizations, who already invested a lot of resources in cloud migration move back workloads to on-premises? I don’t think so.
But no organization, not even major financial organizations like banks or insurance companies, or even the largest multinational enterprises, have enough manpower, knowledge, and budget to invest in proper protection of their own data or their customers’ data, as hyperscale cloud providers.
There are several of reasons for this:
- Hyperscale cloud providers invest billions of dollars improving security controls, including dedicated and highly trained personnel.
- Breach of customers’ data that resides at hyperscale cloud providers can drive a cloud provider out of business, due to breach of customer’s trust.
- Security is important to most organizations; however, it is not their main line of expertise.
Organization need to focus on their core business that brings them value, like manufacturing, banking, healthcare, education, etc., and rethink how to obtain services that support their business goals, such as IT services, but do not add direct value.
Recommendations for managing security
Security Monitoring
Security best practices often state: “document everything”.
There are two downsides to this recommendation: One, storage capacity is limited and two, most organizations do not have enough trained manpower to review the logs and find the top incidents to handle.
Switching security monitoring to cloud-based managed systems such as Azure Sentinel or Amazon GuardDuty, will assist in detecting important incidents and internally handle huge logs.
Encryption
Another security best practice state: “encrypt everything”.
A few years ago, encryption was quite a challenge. Will the service/application support the encryption? Where do we store the encryption key? How do we manage key rotation?
In the past, only banks could afford HSM (Hardware Security Module) for storing encryption keys, due to the high cost.
Today, encryption is standard for most cloud services, such as AWS KMS, Azure Key Vault, Google Cloud KMS and Oracle Key Management.
Most cloud providers, not only support encryption at rest, but also support customer managed key, which allows the customer to generate his own encryption key for each service, instead of using the cloud provider’s generated encryption key.
Security Compliance
Most organizations struggle to handle security compliance over large environments on premise, not to mention large IaaS environments.
This issue can be solved by using managed compliance services such as AWS Security Hub, Azure Security Center, Google Security Command Center or Oracle Cloud Access Security Broker (CASB).
DDoS Protection
Any organization exposing services to the Internet (from publicly facing website, through email or DNS service, till VPN service), will eventually suffer from volumetric denial of service.
Only large ISPs have enough bandwidth to handle such an attack before the border gateway (firewall, external router, etc.) will crash or stop handling incoming traffic.
The hyperscale cloud providers have infrastructure that can handle DDoS attacks against their customers, services such as AWS Shield, Azure DDoS Protection, Google Cloud Armor or Oracle Layer 7 DDoS Mitigation.
Using SaaS Applications
In the past, organizations had to maintain their entire infrastructure, from messaging systems, CRM, ERP, etc.
They had to think about scale, resilience, security, and more.
Most breaches of cloud environments originate from misconfigurations at the customers’ side on IaaS / PaaS services.
Today, the preferred way is to consume managed services in SaaS form.
These are a few examples: Microsoft Office 365, Google Workspace (Formerly Google G Suite), Salesforce Sales Cloud, Oracle ERP Cloud, SAP HANA, etc.
Limit the Blast Radius
To limit the “blast radius” where an outage or security breach on one service affects other services, we need to re-architect infrastructure.
Switching from applications deployed inside virtual servers to modern development such as microservices based on containers, or building new applications based on serverless (or function as a service) will assist organizations limit the attack surface and possible future breaches.
Example of these services: Amazon ECS, Amazon EKS, Azure Kubernetes Service, Google Kubernetes Engine, Google Anthos, Oracle Container Engine for Kubernetes, AWS Lambda, Azure Functions, Google Cloud Functions, Google Cloud Run, Oracle Cloud Functions, etc.
Summary
The bottom line: organizations can increase their security posture, by using the public cloud to better protect their data, use the expertise of cloud providers, and invest their time in their core business to maximize value.
Security breaches are inevitable. Shifting to cloud services does not shift an organization’s responsibility to secure their data. It simply does it better.
Cloud Shell alternatives

What is cloud shell and what is it used for?
Cloud Shell is a browser-based shell, for running Linux commands, scripts, and command line tools, within a cloud environment, without having to install any tools on the local desktop. It contains ephemeral storage for saving configuration and installing software required for performing tasks. But we need to remember that the storage has a capacity limitation and eventually will be erased after a certain amount of idle time.
Cloud Shell Alternatives
| AWS CloudShell | Azure Cloud Shell | Google Cloud Shell | Oracle Cloud Shell | |
| Operating System | Amazon Linux 2 | Ubuntu 16.04 LTS | Debian-based Linux | Oracle Linux |
| Shell interface | Bash, Z shell | Bash | Bash | Bash |
| Scripting interface | PowerShell | PowerShell | – | – |
| CLI Tools installed | AWS CLI, Amazon ECS CLI, AWS SAM CLI | Azure CLI, Azure Functions CLI, Service Fabric CLI, Batch Shipyard | Google App Engine SDK, Google Cloud SDK | OCI CLI |
| Persistent storage for home directory | 1GB | 5GB | 5GB | 5GB |
| Idle inactive termination | 20-30 minutes | 20 minutes | 20 minutes | 20 minutes |
| Maximum data storage | 120 days | – | 120 days | 60 days |
Additional references
- AWS CloudShell
https://aws.amazon.com/cloudshell/features/
- Limits and restrictions for AWS CloudShell
https://docs.aws.amazon.com/cloudshell/latest/userguide/limits.html
- Azure Cloud Shell
https://docs.microsoft.com/en-us/azure/cloud-shell/features
- Troubleshooting & Limitations of Azure Cloud Shell
https://docs.microsoft.com/en-us/azure/cloud-shell/troubleshooting
- Google Cloud Shell
https://cloud.google.com/shell/docs
- Limitations and restrictions of Google Cloud Shell
https://cloud.google.com/shell/docs/limitations
- Oracle Cloud Infrastructure (OCI) Cloud Shell
https://docs.oracle.com/en-us/iaas/Content/API/Concepts/cloudshellintro.htm
- OCI Cloud Shell Limitations
https://docs.oracle.com/en-us/iaas/Content/API/Concepts/cloudshellintro.htm#Cloud_Shell_Limitations
Importance of cloud strategy

Why do organizations need a cloud strategy and what are the benefits?
In this post, we will review some of the reasons for defining and committing an organizational cloud strategy to print, what topics should be included in such a document and how a cloud strategy enables organizations to manage risks involved in achieving secure and smart cloud usage to promote business goals.
Terminology
A cloud strategy document should include a clear definition of what is considered a cloud service, based on the NIST definition:
- On demand self-service – A consumer can unilaterally provision computing capabilities, such as server time and network storage, as needed automatically without requiring human interaction with each service provider
- Broad network access – Capabilities are available over the network and accessed through standard mechanisms that promote use by heterogeneous thin or thick client platforms (e.g., mobile phones, tablets, laptops, and workstations)
- Resource pooling – The provider’s computing resources are pooled to serve multiple consumers using a multi-tenant model, with different physical and virtual resources dynamically assigned and reassigned according to consumer demand. There is a sense of location independence in that the customer generally has no control or knowledge over the exact location of the provided resources but may be able to specify location at a higher level of abstraction (e.g., country, state, or datacenter). Examples of resources include storage, processing, memory, and network bandwidth
- Rapid elasticity – Capabilities can be elastically provisioned and released, in some cases automatically, to scale rapidly outward and inward commensurate with demand. To the consumer, the capabilities available for provisioning often appear to be unlimited and can be appropriated in any quantity at any time
- Measured service – Cloud systems automatically control and optimize resource use by leveraging a metering capability at some level of abstraction appropriate to the type of service (e.g., storage, processing, bandwidth, and active user accounts). Resource usage can be monitored, controlled, and reported, providing transparency for both the provider and consumer of the utilized service
The cloud strategy document should include a clear definition of what is not considered a cloud service – such as hosting services provided by hardware vendors (hosting service / hosting facility, Virtual Private Servers / VPS, etc.)
Business Requirements
The purpose of cloud strategy document is to guide the organization in the various stages of using or migrating to cloud services, while balancing the benefits for the organization and conducting proper risk management at the same time.
Lack of a cloud strategy will result in various departments in the organization consuming cloud services for various reasons, such as an increase productivity, but without official policy on how to properly adopt the cloud services. New IT departments could be created (AKA “Shadow IT”), without any budget control, while increasing information security risks due to lack of guidance.
A cloud strategy document should include the following:
- The benefits for the organization as result of using cloud services
- Definitions of which services will remain on premise and which services can be consumed as cloud services
- Approval process for consuming cloud services
- Risks resulting from using unapproved cloud services
- Required controls to minimize the risks of using cloud services (information security and privacy, cost management, resource availability, etc.)
- Current state (in terms of cloud usage)
- Desired state (where the organization is heading in the next couple of years in terms of cloud usage)
- Exit strategy
Benefits for the organization
Cloud strategy document should include possible benefits from using cloud services, such as:
- Cost savings
- Switching to flexible payment – customer pays for what he is consuming (on demand)
- Information security
- Moving to cloud services, shifts the burden of physical security to the cloud provider
- Using cloud services allows better protection against denial-of-service attacks
- Using cloud services allows access to managed security services (such as security monitoring, breach detection, anomaly, and user behavior detection, etc.) available as part of the leader cloud provider’s portfolio
- Business continuity and disaster recovery
- Cloud infrastructure services (IaaS) are good alternative for deploying DR site
- Infrastructure flexibility
- Using cloud services, allows scale out and scale in the number of resources (from Web servers to database clusters) according to application load
Approval process for consuming cloud services
To formalize the use of cloud services for all departments of the organization, the cloud strategy document should define the approval process for using cloud services (according to organization’s size and maturity level)
- CIO / CTO / IT Manager
- Legal counsel / DPO / Chief risk officer
- Purchase department / Finance
Risk Management
A cloud strategy document should include a mapping of risks in using cloud services, such as:
- Lack of budget control
- The ability of each department, to use credit card details to open an account in the public cloud and begin consuming services without budget control from the finance department
- Regulation and privacy aspects
- Using cloud services for storing personal information (PII) without control by a DPO (or someone in charge of data protection aspects in the organization). This exposes the organization to both breach attempts and violation of privacy laws and regulation
- Information security aspects
- Using cloud services accessible by Internet visitors exposes the organization to data breach, data corruption, deletion, service downtime, reputation damage, etc.
- Lack of knowledge
- Use of cloud services requires proper training in IT, development, support, and information security teams on the proper usage of cloud services
Controls for minimizing the risk out of cloud services usage
The best solution for minimizing the risks to the organization is to create a dedicated team (CCOE – Cloud Center of Excellence) with representatives of the following departments:
- Infrastructure
- Information security
- Legal
- Development
- Technical support
- Purchase department / FinOps
Current state
The cloud strategy document should map the following current state in terms of cloud service usage:
- Which SaaS applications are currently being consumed by the organization and for what purposes?
- Which IaaS / PaaS services are currently being consumed? (Dev / Test environments, etc.)
Desired state
Cloud strategy document should define where the organization going in the next 2-5 years in terms of cloud service usage.
The document should answer these pivotal questions:
- Does the organization wish to continue to manage and maintain infrastructure on its own or migrate to managed services in the cloud?
- Should the organization deploy private cloud?
- Should the organization migrate all applications and infrastructure to the public cloud or perhaps a combination of on premise and public cloud (Hybrid cloud)?
And lastly, the strategy document should define KPIs for successful deployment of cloud services.
Exit strategy
A section should be included that addresses vendor lock-in risks and how to act if the organization chooses to migrate a system from the public cloud back to the on premise, or even migrate data between different public cloud providers for reasons such as cost, support, technological advantage, regulation, etc.
It is important to take extra care of the following topics during contractual agreement with public cloud provider:
- Is there an expected fine for scenarios if the organization decides to end the contract early?
- What is the process of exporting data from a SaaS application back to on premise (or between public cloud providers)?
- What is the public cloud providers commitment for data deletion at the end of the contractual agreement?
- How long is the cloud provider going to store organizational (and customer) data (including backup and logs) after the end of the contractual agreement?
