Archive for the ‘Containers’ Category
Introduction to Serverless Container Services

When developing modern applications, we almost immediately think about wrapping our application components inside Containers — it may not be the only architectural alternative, but a very common one.
Assuming our developers and DevOps teams have the required expertise to work with Containers, we still need to think about maintaining the underlying infrastructure — i.e., the Container hosts.
If our application has a steady and predictable load, and assuming we do not have experience maintaining Kubernetes clusters, and we do not need the capabilities of Kubernetes, it is time to think about an easy and stable alternative for deploying our applications on top of Containers infrastructure.
In the following blog post, I will review the alternatives of running Container workloads on top of Serverless infrastructure.
Why do we need Serverless infrastructure for running Container workloads?
Container architecture is made of a Container engine (such as Docker, CRI-O, etc.) deployed on top of a physical or virtual server, and on top of the Container engine, we deploy multiple Container images for our applications.
The diagram below shows a common Container architecture:
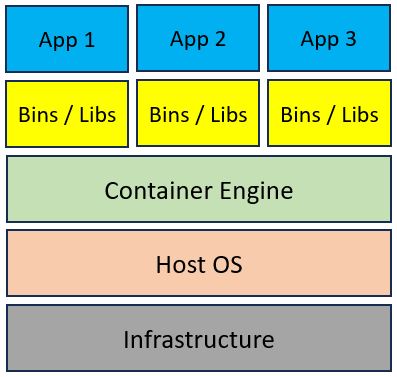
If we focus on the Container engine and the underlying operating system, we understand that we still need to maintain the operating system itself.
Common maintenance tasks for the operating system:
- Make sure it has enough resources (CPU, memory, storage, and network connectivity) for running Containers
- Make sure the operating system is fully patched and hardened from external attacks
- Make sure our underlying infrastructure (i.e., Container host nodes), provides us with high availability in case one of the host nodes fails and needs to be replaced
- Make sure our underlying infrastructure provides us the necessary scale our application requires (i.e., scale out or in according to application load)
Instead of having to maintain the underlying host nodes, we should look for a Serverless solution, that allows us to focus on application deployment and maintenance and decrease as much as possible the work on maintaining the infrastructure.
Comparison of Serverless Container Services
Each of the hyperscale cloud providers offers us the ability to consume a fully managed service for deploying our Container-based workloads.
Below is a comparison of AWS, Azure, and Google Cloud alternatives:
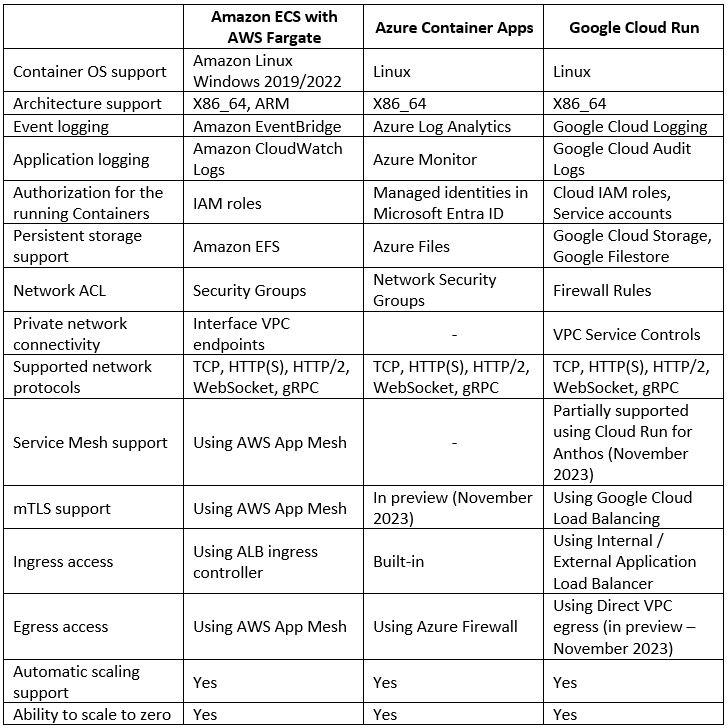
Side notes for Azure users
While researching for this blog post, I had a debate about whether to include Azure Containers Apps or Azure Container Instances.
Although both services allow customers to run Containers in a managed environment, Azure Container Instances is more suitable for running a single Container application, while Azure Container Apps allows customers to build a full microservice-based application.
Summary
In this blog post, I have compared alternatives for deploying microservice architecture on top of Serverless Container services offered by AWS, Azure, and GCP.
While designing your next application based on microservice architecture, and assuming you don’t need a full-blown Kubernetes cluster (with all of its features and complexities), consider using Serverless Container service.
References
About the Author
Eyal Estrin is a cloud and information security architect, and the author of the book Cloud Security Handbook, with more than 20 years in the IT industry. You can connect with him on Twitter.
Opinions are his own and not the views of his employer.
Introduction to Chaos Engineering

In the past couple of years, we hear the term “Chaos Engineering” in the context of cloud.
Mature organizations have already begun to embrace the concepts of chaos engineering, and perhaps the most famous use of chaos engineering began at Netflix when they developed Chaos Monkey.
To quote Werner Vogels, Amazon CTO: “Everything fails, all the time”.
What is chaos engineering and what are the benefits of using chaos engineering for increasing the resiliency and reliability of workloads in the public cloud?
What is Chaos Engineering?
“Chaos Engineering is the discipline of experimenting on a system to build confidence in the system’s capability to withstand turbulent conditions in production.” (Source: https://principlesofchaos.org)
Production workloads on large scale, are built from multiple services, creating distributed systems.
When we design large-scale workloads, we think about things such as:
- Creating high-available systems
- Creating disaster recovery plans
- Decreasing single point of failure
- Having the ability to scale up and down quickly according to the load on our application
One thing we usually do not stop to think about is the connectivity between various components of our application and what will happen in case of failure in one of the components of our application.
What will happen if, for example, a web server tries to access a backend database, and it will not be able to do so, due to network latency on the way to the backend database?
How will this affect our application and our customers?
What if we could test such scenarios on a live production environment, regularly?
Do we trust our application or workloads infrastructure so much, that we are willing to randomly take down parts of our infrastructure, just so we will know the effect on our application?
How will this affect the reliability of our application, and how will it allow us to build better applications?
History of Chaos Engineering
In 2010 Netflix developed a tool called “Chaos Monkey“, whose goal was to randomly take down compute services (such as virtual machines or containers), part of the Netflix production environment, and test the impact on the overall Netflix service experience.
In 2011 Netflix released a toolset called “The Simian Army“, which added more capabilities to the Chaos Monkey, from reliability, security, and resiliency (i.e., Chaos Kong which simulates an entire AWS region going down).
In 2012, Chaos Monkey became an open-source project (under Apache 2.0 license).
In 2016, a company called Gremlin released the first “Failure-as-a-Service” platform.
In 2017, the LitmusChaos project was announced, which provides chaos jobs in Kubernetes.
In 2019, Alibaba Cloud announced ChaosBlade, an open-source Chaos Engineering tool.
In 2020, Chaos Mesh 1.0 was announced as generally available, an open-source cloud-native chaos engineering platform.
In 2021, AWS announced the general availability of AWS Fault Injection Simulator, a fully managed service to run controlled experiments.
In 2021, Azure announced the public preview of Azure Chaos Studio.
What exactly is Chaos Engineering?
Chaos Engineering is about experimentation based on real-world hypotheses.
Think about Chaos Engineering, as one of the tests you run as part of a CI/CD pipeline, but instead of a unit test or user acceptance test, you inject controlled faults into the system to measure its resiliency.
Chaos Engineering can be used for both modern cloud-native applications (built on top of Kubernetes) and for the legacy monolith, to achieve the same result – answering the question – will my system or application survive a failure?
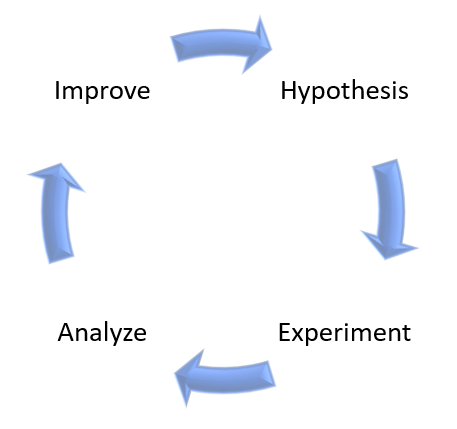
On high-level, Chaos Engineering is made of the following steps:
- Create a hypothesis
- Run an experiment
- Analyze the results
- Improve system resiliency
As an example, here is AWS’s point of view regarding the shared responsibility model, in the context of resiliency:
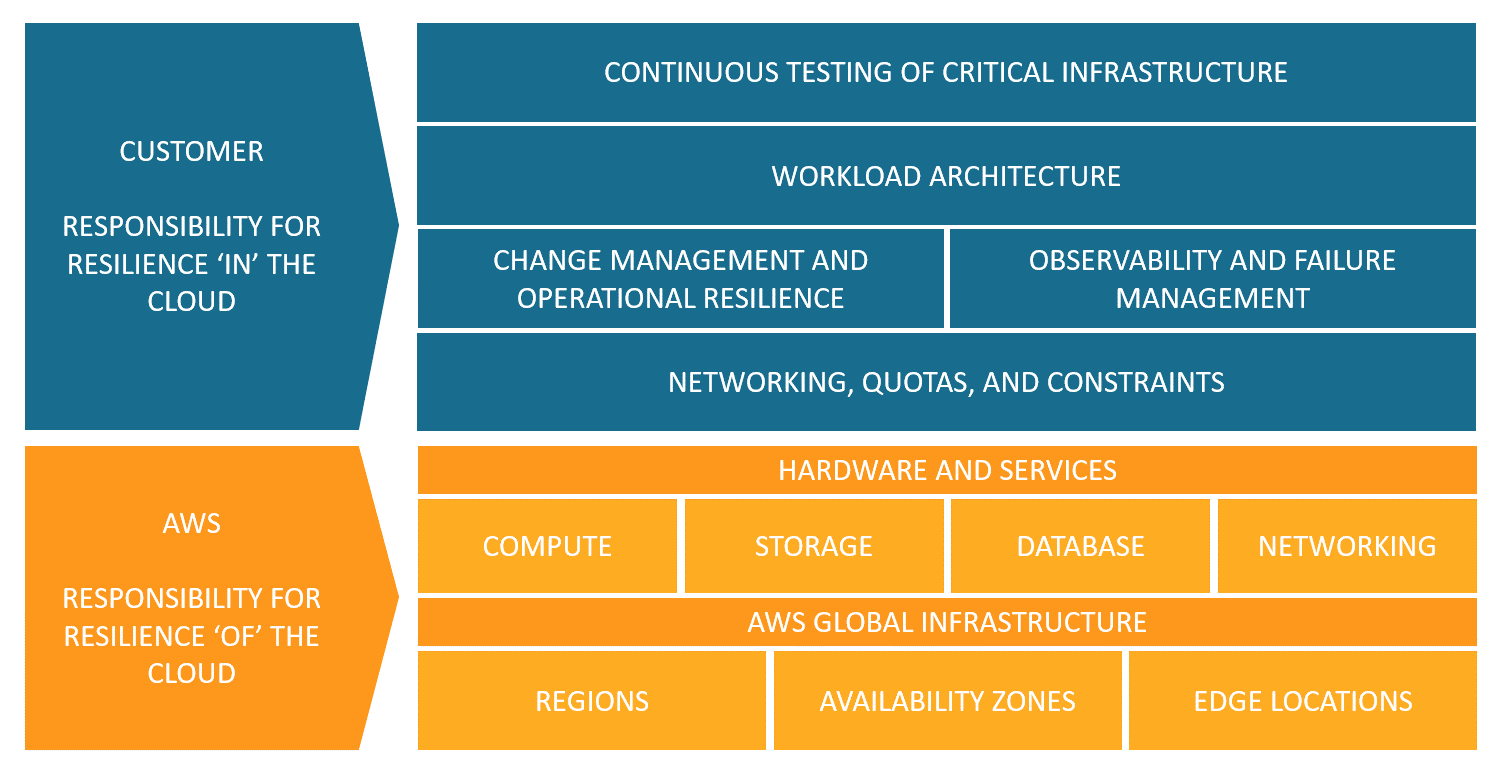
Source: https://aws.amazon.com/blogs/architecture/chaos-engineering-in-the-cloud
Chaos Engineering managed platform comparison
In the table below we can see a comparison between AWS and Azure-managed services for running Chaos Engineering experiments:

Additional References:
Summary
In this post, I have explained the concept of Chaos Engineering and compared alternatives to cloud-managed services.
Using Chaos Engineering as part of a regular development process will allow you to increase the resiliency of your applications, by studying the effect of failures and designing recovery processes.
Chaos Engineering can also be used as part of a disaster recovery and business continuity process, by testing the resiliency of your systems.
Additional References
- Chaos engineering (Wikipedia)
- Principles of Chaos Engineering
- Chaos Engineering in the Cloud
- What Chaos Engineering Is (and is not)
- AWS re:Invent 2022 – The evolution of chaos engineering at Netflix (NFX303)
- What is AWS Fault Injection Simulator?
- What is Azure Chaos Studio?
- Public Chaos Engineering Stories / Implementations
Introduction to Day 2 Kubernetes

Over the years, I have shared several blog posts about Kubernetes (What are Containers and Kubernetes, Modern Cloud deployment and usage, Introduction to Container Operating Systems, and more).
Kubernetes became a de-facto standard for running container-based workloads (for both on-premise and the public cloud), but most organizations tend to fail on what is referred to as Day 2 Kubernetes operations.
In this blog post, I will review what it means “Day 2 Kubernetes” and how to prepare your workloads for the challenges of Day 2 operations.
Ready, Set, Go!
In the software lifecycle, or the context of this post, the Kubernetes lifecycle, there are several distinct stages:
Day 0 – Planning and Design
In this stage, we focus on designing our solution (application and underlying infrastructure), understanding business needs, budget, required skills, and more.
For the context of this post, let us assume we have decided to build a cloud-native application, made of containers, deployed on top of Kubernetes.
Day 1 – Configuration and Deployment
In this stage, we focus on deploying our application using the Kubernetes orchestrator and setting up the configurations (number of replicas, public ports, auto-scale settings, and more).
Most organizations taking their first steps deploying applications on Kubernetes are stacked at this stage.
They may have multiple environments (such as Dev, Test, UAT) and perhaps even production workloads, but they are still on Day 1.
Day 2 – Operations
Mature organizations have reached this stage.
This is about ongoing maintenance, observability, and continuous improvement of security aspects of production workloads.
In this blog post, I will dive into “Day 2 Kubernetes”.
Day 2 Kubernetes challenges
Below are the most common Kubernetes challenges:
Observability
Managing Kubernetes at a large scale requires insights into the Kubernetes cluster(s).
It is not enough to monitor the Kubernetes cluster by collecting performance logs, errors, or configuration changes (such as Nodes, Pods, containers, etc.)
We need to have the ability to truly understand the internals of the Kubernetes cluster (from logs, metrics, etc.), be able to diagnose the behavior of the Kubernetes cluster – not just performance issues, but also debug problems, detect anomalies, and (hopefully) be able to anticipate problems before they affect customers.
Prefer to use cloud-native monitoring and observability tools to monitor Kubernetes clusters.
Without proper observability, we will not be able to do root cause analysis and understand problems with our Kubernetes cluster or with our application deployed on top of Kubernetes.
Common tools for observability:
- Prometheus – An open-source systems monitoring and alerting toolkit for monitoring large cloud-native deployments.
- Grafana – An open-source query, visualization, and alerting tool (resource usage, built-in and customized metrics, alerts, dashboards, log correlation, etc.)
- OpenTelemetry – A collection of open-source tools for collecting and exporting telemetry data (metrics, logs, and traces) for analyzing software performance and behavior.
Additional references for managed services:
- Amazon Managed Grafana
- Amazon Managed Service for Prometheus
- AWS Distro for OpenTelemetry
- Azure Monitor managed service for Prometheus (Still in preview on April 2023)
- Azure Managed Grafana
- OpenTelemetry with Azure Monitor
- Google Cloud Managed Service for Prometheus
- Google Cloud Logging plugin for Grafana
- OpenTelemetry Collector (Part of Google Cloud operations suite)
Security and Governance
On the one hand, it is easy to deploy a Kubernetes cluster in private mode, meaning, the API server or the Pods are on an internal subnet and not directly exposed to customers.
On the other hand, many challenges in the security domain need to be solved:
- Secrets Management – A central and secure vault for generating, storing, retrieving, rotating, and eventually revoking secrets (instead of hard-coded static credentials inside our code or configuration files).
- Access control mechanisms – Ability to control what persona (either human or service account) has access to which resources inside the Kubernetes cluster and to take what actions, using RBAC (Role-based access control) mechanisms.
- Software vulnerabilities – Any vulnerabilities related to code – from programming languages (such as Java, PHP, .NET, NodeJS, etc.), use of open-source libraries with known vulnerabilities, to vulnerabilities inside Infrastructure-as-Code (such as Terraform modules)
- Hardening – Ability to deploy a Kubernetes cluster at scale, using secured configuration, such as CIS Benchmarks.
- Networking – Ability to set isolation between different Kubernetes clusters or even between different development teams using the same cluster, not to mention multi-tenancy where using the same Kubernetes platform to serve different customers.
Additional Reference:
- Securing the Software Supply Chain in the Cloud
- OPA (Open Policy Agent) Gatekeeper
- Kyverno – Kubernetes Native Policy Management
- Foundational Cloud Security with CIS Benchmarks
- Amazon EKS Best Practices Guide for Security
- Azure security baseline for Azure Kubernetes Service (AKS)
- GKE Security Overview
Developers experience
Mature organizations have already embraced DevOps methodologies for pushing code through a CI/CD pipeline.
The entire process needs to be done automatically and without direct access of developers to production environments (for this purpose you build break-glass mechanisms for the SRE teams).
The switch to applications wrapped inside containers, allowed developers to develop locally or in the cloud and push new versions of their code to various environments (such as Dev, Test, and Prod).
Integration of CI/CD pipeline, together with containers, allows organizations to continuously develop new software versions, but it requires expanding the knowledge of developers using training.
The use of GitOps and tools such as Argo CD allowed a continuous delivery process for Kubernetes environments.
To allow developers, the best experience, you need to integrate the CI/CD process into the development environment, allowing the development team the same experience as developing any other application, as they used to do in the on-premise for legacy applications, which can speed the developer onboarding process.
Additional References:
- GitOps 101: What is it all about?
- Argo CD – Declarative GitOps CD for Kubernetes
- Continuous Deployment and GitOps delivery with Amazon EKS Blueprints and ArgoCD
- Getting started with GitOps, Argo, and Azure Kubernetes Service
- Building a Fleet of GKE clusters with ArgoCD
Storage
Any Kubernetes cluster requires persistent storage – whether organizations choose to begin with an on-premise Kubernetes cluster and migrate to the public cloud, or provision a Kubernetes cluster using a managed service in the cloud.
Kubernetes supports multiple types of persistent storage – from object storage (such as Azure Blob storage or Google Cloud Storage), block storage (such as Amazon EBS, Azure Disk, or Google Persistent Disk), or file sharing storage (such as Amazon EFS, Azure Files or Google Cloud Filestore).
The fact that each cloud provider has its implementation of persistent storage adds to the complexity of storage management, not to mention a scenario where an organization is provisioning Kubernetes clusters over several cloud providers.
To succeed in managing Kubernetes clusters over a long period, knowing which storage type to use for each scenario, requires storage expertise.
High Availability
High availability is a common requirement for any production workload.
The fact that we need to maintain multiple Kubernetes clusters (for example one cluster per environment such as Dev, Test, and Prod) and sometimes on top of multiple cloud providers, make things challenging.
We need to design in advance where to provision our cluster(s), thinking about constraints such as multiple availability zones, and sometimes thinking about how to provision multiple Kubernetes clusters in different regions, while keeping HA requirements, configurations, secrets management, and more.
Designing and maintaining HA in Kubernetes clusters requires a deep understanding of Kubernetes internals, combined with knowledge about specific cloud providers’ Kubernetes management plane.
Additional References:
- Designing Production Workloads in the Cloud
- Amazon EKS Best Practices Guide for Reliability
- AKS – High availability Kubernetes cluster pattern
- GKE best practices: Designing and building highly available clusters
Cost optimization
Cost is an important factor in managing environments in the cloud.
It can be very challenging to design and maintain multiple Kubernetes clusters while trying to optimize costs.
To monitor cost, we need to deploy cost management tools (either the basic services provided by the cloud provider) or third-party dedicated cost management tools.
For each Kubernetes cluster, we need to decide on node instance size (amount of CPU/Memory), and over time, we need to review the node utilization and try to right-size the instance type.
For non-production clusters (such as Dev or Test), we need to understand from the cloud vendor documentation, what are our options to scale the cluster size to the minimum, when not in use, and be able to spin it back up, when required.
Each cloud provider has its pricing options for provisioning Kubernetes clusters – for example, we might want to choose reserved instances or saving plans for production clusters that will be running 24/7, while for temporary Dev or Test environment, we might want to choose Spot instances and save cost.
Additional References:
- Cost optimization for Kubernetes on AWS
- Azure Kubernetes Service (AKS) – Cost Optimization Techniques
- Best practices for running cost-optimized Kubernetes applications on GKE
- 5 steps to bringing Kubernetes costs in line
- 4 Strategies for Kubernetes Cost Reduction
Knowledge gap
Running Kubernetes clusters requires a lot of knowledge.
From the design, provision, and maintenance, usually done by DevOps or experienced cloud engineers, to the deployment of new applications, usually done by development teams.
It is crucial to invest in employee training, in all aspects of Kubernetes.
Constant updates using vendor documentation, online courses, blog posts, meetups, and technical conferences will enable teams to gain the knowledge required to keep up with Kubernetes updates and changes.
Additional References:
- Kubernetes Blog
- AWS Containers Blog
- Azure Kubernetes Service (AKS) issue and feature tracking
- Google Cloud Blog – Containers & Kubernetes
Third-party integration
Kubernetes solve part of the problems related to container orchestration.
As an open-source solution, it can integrate with other open-source complimentary solutions (from monitoring, security and governance, cost management, and more).
Every organization might wish to use a different set of tools to achieve each task relating to the ongoing maintenance of the Kubernetes cluster or for application deployment.
Selecting the right tools can be challenging as well, due to various business or technological requirements.
It is recommended to evaluate and select Kubernetes native tools to achieve the previously mentioned tasks or resolve the mentioned challenges.
Summary
In this blog post, I have reviewed the most common Day 2 Kubernetes challenges.
I cannot stress enough the importance of employee training in deploying and maintaining Kubernetes clusters.
It is highly recommended to evaluate and look for a centralized management platform for deploying, monitoring (using cloud-native tools), and securing the entire fleet of Kubernetes clusters in the organization.
Another important recommendation is to invest in automation – from policy enforcement to application deployment and upgrade, as part of the CI/CD pipeline.
I recommend you continue learning and expanding your knowledge in the ongoing changed world of Kubernetes.
Introduction to Container Operating Systems
Working with modern computing environments based on containers offers a lot of benefits (from small image footprint, fast deployment/decommission, and more), but it also has its challenges (from software/package update process, security, integration with container orchestrators, and more).
In this blog post, I will review container operating systems, what are their benefits in the modern cloud environment, and how AWS compares to Google Cloud in terms of container operating systems.
What is Container Operating-Systems?
Container OS is a special type of Linux OS, dedicated to running container workloads.
Below are some of the benefits of using Container OS:
- Small OS footprint – Container OS includes only the necessary packages and dependencies for running containers
- Optimized performance – Container OS is optimized specifically to run container workloads
- Immutable root filesystem – The root filesystem is mounted as read-only. No changes can be done to the root filesystem
- Remote control – SSH to the Container OS is disabled by default
- Automatic updates – Container OS software updates are done using the CSP-managed containers or Kubernetes service upgrade mechanisms
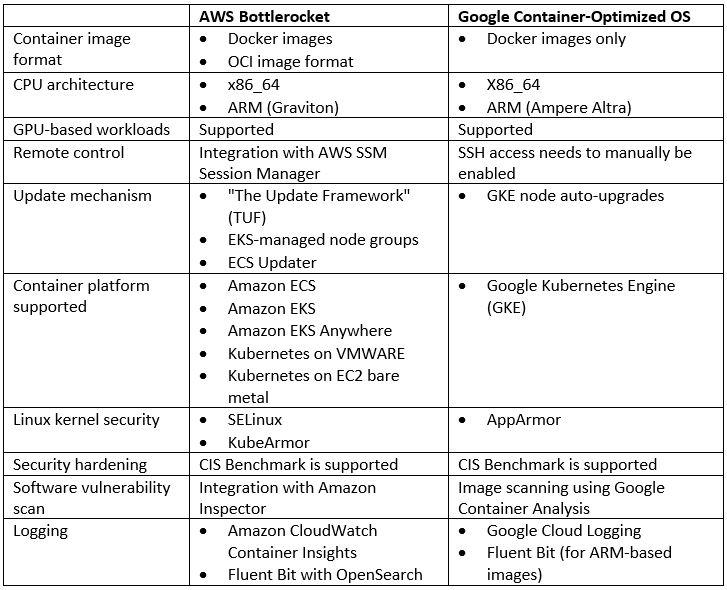
AWS Bottlerocket vs. Google Container-Optimized OS
Summary
Container operating systems are considered the last word in the evolution of hypervisors, optimized to run container workloads.
Their small footprint, built-in security features, auto-update, and integration with managed Kubernetes services make them idle for running container workloads.
Although both Bottlerocket and Container-Optimized OS were created by specific cloud providers, AWS Bottlerocket does offer much broader alternatives for running a container OS on various container platforms.
References
- AWS Bottlerocket
https://aws.amazon.com/bottlerocket/
- Google Container-Optimized OS
Cloud Native Applications – Part 1: Introduction

In the past couple of years, there is a buzz about cloud-native applications.
In this series of posts, I will review what exactly is considered a cloud-native application and how can we secure cloud-native applications.
Before speaking about cloud-native applications, we should ask ourselves – what is cloud native anyway?
The CNCF (Cloud Native Computing Foundation) provides the following definition:
“Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.”
Source: https://github.com/cncf/toc/blob/main/DEFINITION.md
It means – taking full advantage of cloud capabilities, from elasticity (scale in and scale out according to workload demands), use of managed services (such as compute, database, and storage services), and the use of modern design architectures based on micro-services, APIs, and event-driven applications.
What are the key characteristics of cloud-native applications?
Use of modern design architecture
Modern applications are built from loosely coupled architecture, which allows us to replace a single component of the application, with minimal or even no downtime to the entire application.
Examples can be code update/change or scale in/scale out a component according to application load.
- RESTful APIs are suitable for communication between components when fast synchronous communication is required. We use API gateways as managed service to expose APIs and control inbound traffic to various components of our application.
Example of services:
- Amazon API Gateway
- Azure API Management
- Google API Gateway
- Oracle API Gateway
- Event-driven architecture is suitable for asynchronous communication. It uses events to trigger and communicate between various components of our application. In this architecture, one component produces/publishes an event (such as a file uploaded to object storage) and another component subscribes/consumes the events (in a Pub/Sub model) and reacts to the event (for example reads the file content and steam it to a database). This type of architecture handles load very well.
Example of services:
- Amazon EventBridge
- Amazon Simple Queue Service (SQS)
- Azure Event Grid
- Azure Service Bus
- Google Eventarc
- Google Cloud Pub/Sub
- Oracle Cloud Infrastructure (OCI) Events Service
Additional References:
- AWS – What is API management?
- AWS – What is an Event-Driven Architecture?
- Azure – API Design
- Azure – Event-driven architecture style
- Google API design guide
- GCP – Event-driven architectures
- Oracle API For Developers
- Oracle Cloud – Modern App Development – Event-Driven
Use of microservices
Microservices represent the concept of distributed applications, and they enable us to decouple our applications into small independent components.
Components in a microservice architecture usually communicate using APIs (as previously mentioned in this post).
Each component can be deployed independently, which provides a huge benefit for code change and scalability.
Additional references:
- AWS – What are Microservices?
- Azure – Microservice architecture style
- GCP – What is Microservices Architecture?
- Oracle Cloud – Design a Microservices-Based Application
- The Twelve-Factor App
Use of containers
Modern applications are heavily built upon containerization technology.
Containers took virtual machines to the next level in the evolution of computing services.
They contain a small subset of the operating system – only the bare minimum binaries and libraries required to run an application.
Containers bring many benefits – from the ability to run anywhere, small footprint (for container images), isolation (in case of a container crash), fast deployment time, and more.
The most common orchestration and deployment platform for containers is Kubernetes, used by many software development teams and SaaS vendors, capable of handling thousands of containers in many production environments.
Example of services:
- Amazon Elastic Kubernetes Service (EKS)
- Azure Kubernetes Service (AKS)
- Google Kubernetes Engine (GKE)
- Oracle Container Engine for Kubernetes (OKE)
Additional References:
Use of Serverless / Function as a Service
More and more organizations are beginning to embrace serverless or function-as-a-service technology.
This is considered the latest evolution in computing services.
This technology allows us to write code and import it into a managed environment, where the cloud provider is responsible for the maintenance, availability, scalability, and security of the underlining infrastructure used to run our code.
Serverless / Function as a Service, demonstrates a very good use case for event-driven applications (for example – an event written to a log file triggers a function to update a database record).
Functions can also be part of a microservice architecture, where some of the application components are based on serverless technology, to run specific tasks.
Example of services:
Additional References:
- Serverless on AWS
- Azure serverless
- Google Cloud Serverless computing
- Oracle Cloud – What is serverless?
Use of DevOps processes
To support rapid application development and deployment, modern applications use CI/CD processes, which follow DevOps principles.
We use pipelines to automate the process of continuous integration and continuous delivery or deployment.
The process allows us to integrate multiple steps or gateways, where in each step we can embed additional automated tests, from static code analysis, functional test, integration test, and more.
Example of services:
Additional References:
Use of automated deployment processes
Modern application deployment takes an advantage of automation using Infrastructure as Code.
Infrastructure as Code is using declarative scripting languages, in in-order to deploy an entire infrastructure or application infrastructure stack in an automated way.
The fact that our code is stored in a central repository allows us to enforce authorization mechanisms, auditing of actions, and the ability to roll back to the previous version of our Infrastructure as Code.
Infrastructure as Code integrates perfectly with CI/CD processes, which enables us to re-use the knowledge we already gained from DevOps principles.
Example of solutions:
Additional References:
- Automation as key to cloud adoption success
- AWS – Infrastructure as Code
- Azure – What is infrastructure as code (IaC)?
- Want a repeatable scale? Adopt infrastructure as code on GCP
- Oracle Cloud – What Is Infrastructure as Code (IaC)?
Summary
In this post, we have reviewed the key characteristics of cloud-native applications, and how can we take full advantage of the cloud, when designing, building, and deploying modern applications.
I recommend you continue expanding your knowledge about cloud-native applications, whether you are a developer, IT team member, architect, or security professional.
Stay tuned for the next chapter of this series, where we will focus on securing cloud-native applications.
Additional references
Mitigating the risk of a cloud outage or lack of cloud resources

Organizations migrating to the public cloud, or already provisioning workloads in the cloud come across limitations, either on production workloads or issues published in the media, as you can read below:


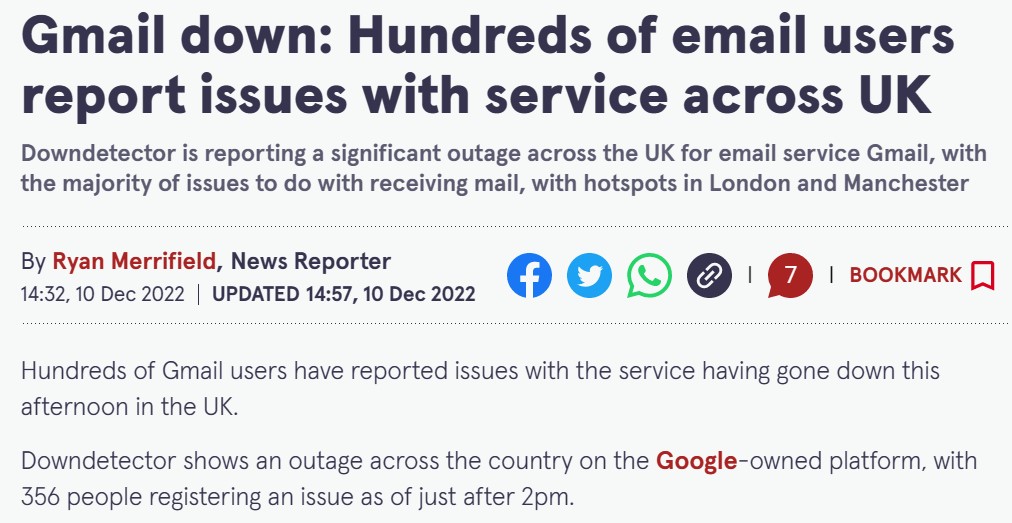

As a cloud consumer, you might be asking yourself, how do I mitigate such risks from affecting my production workloads? (Assuming your organization has already invested a lot of money and resources in the public cloud)
There is no one answer to this question, but in the following post, I will try to review some of the alternatives for protecting yourself or at least try to mitigate the risks.
Alternative 1 – Switching to a cloud-native application
This alternative takes full advantage of cloud benefits.
Instead of using VMs to run or process your workload, you will have to re-architect your application and use cloud-native services such as Serverless / Function as Service, managed services (from serverless database services, object storage, etc.), and event-driven services (such as Pub/Sub, Kafka, etc.)
Pros
- You decrease your application dependencies on virtual machines (on-demand, reserved instances, and even Spot instances), so resource allocation limits of VMs should be less concerning.
Cons
- Full re-architecture of your applications can be an expensive and time-consuming process. It requires a deep review of the entire application stack, understanding the application requirements and limitations, and having an experienced team of developers, DevOps, architects, and security personnel, knowledgeable enough about your target cloud providers ecosystem.
- The more you use a specific cloud’s ecosystem (such as proprietary Serverless / Function as a Service), the higher your dependency on specific cloud technology, which will cause challenges in case you are planning to switch to another cloud provider sometime in the future (or consider the use of multi-cloud).
Additional references:
- AWS – What Is Cloud Native?
- Azure – What is Cloud Native?
- Google Cloud – What is cloud-native?
- Oracle Cloud – What is Cloud Native?
Alternative 2 – The multi-region architecture
This alternative suggests designing a multi-region architecture, where you use several (separate) regions from your cloud provider of choice.
Pros
- The use of multi-region architecture will decrease the chance of having an outage of your services or the chance of having resource allocation issues.
Cons
- In case the cloud provider fails to create a complete separation between his regions (see: https://www.theguardian.com/technology/2020/dec/14/google-suffers-worldwide-outage-with-gmail-youtube-and-other-services-down), multi-region architecture will not resolve potential global outage issues (or limit the blast radius).
- In case you have local laws or regulations which force you to store personal data on data centers in a specific jurisdiction, a multi-region solution is not an option.
- Most IaaS / PaaS services offered today by cloud providers are regional, meaning, they are limited to a specific region and do not span across regions, and as a result, you will have to design a plan for data migration or synchronization across regions, which increases the complexity of maintaining this architecture.
- In a multi-region architecture, you need to take into consideration the cost of egress data between separate regions.
Additional references:
- AWS – Multi-Region Application Architecture
- Azure – Multi-region N-tier application
- Google Cloud – Creating multi-region deployments for API Gateway
- Oracle Cloud – Implementing a high-availability architecture in and across regions
- Using the Cloud to build multi-region architecture
Alternative 3 – Cloud agnostic architecture (or preparation for multi-cloud)
This alternative suggests using services that are available for all major cloud providers.
An example can be – to package your application inside containers and manage the containers orchestration using a Kubernetes-managed service (such as Amazon EKS, Azure AKS, Google GKE, or Oracle OKE).
To enable cloud agnostic architecture from day 1, consider provisioning all resources using HashiCorp Terraform – both for Kubernetes resources and any other required cloud service, with the relevant adjustments for each of the target cloud providers.
Pros
- Since container images can be stored in a container registry of your choice, you might be able to migrate between cloud providers.
Cons
- Using Kubernetes might resolve the problem of using the same underlining orchestrator engine, but you will still need to think about the entire cloud provider ecosystem (from data store services, queuing services, caching, identity authentication and authorization services, and more.
- In case you have already invested a lot of resources in a specific cloud provider and already stored a large amount of data in a specific cloud provider’s storage service, migrating to another cloud provider will be an expensive move, not to mention the cost of egress data between different cloud providers.
- You will have to invest time in training your teams on working with several cloud providers’ infrastructures and maintain several copies of your Terraform code, to suit each cloud provider infrastructure.
Summary
Although there is no full-proof answer to the question “How do I protect myself from the risk of a cloud outage or lack of cloud resources”, we need to be aware of both types of risks.
We need to be able to explain the risks and the different alternatives provided in this post and explain them to our organization’s top management.
Once we understand the risks and the pros and cons of each alternative, our organization will be able to decide how to manage the risk.
I truly believe that the future of IT is in the public cloud, but migrating to the cloud blindfolded, is the wrong way to fully embrace the potential of the public cloud.
Using immutable infrastructure to achieve cloud security

Maintaining cloud infrastructure, especially compute components, requires a lot of effort – from patch management, secure configuration, and more.
Other than the efforts it takes for the maintenance part, it simply will not scale.
Will we be able to support our workloads when we need to scale to thousands of machines at peak?
Immutable infrastructure is a deployment method where compute components (virtual machines, containers, etc.) are never updated – we simply replace a running component with a new one and decommission the old one.
Immutable infrastructure has its advantages, such as:
- No dependent on previous VM/container state
- No configuration drifts
- The fast configuration management process
- Easy horizontal scaling
- Simple rollback/recovery process
The Twelve-Factor App
Designing modern or cloud-native applications requires us to follow 12 principles, documents in https://12factor.net
Looking at this guide, we see that factor number 3 (config) guides us to store configuration in environment variables, outside our code (or VMs/containers).
For further reading, see:
- The Twelve-Factor App – Config
- AWS – Applying the Twelve-Factor App Methodology to Serverless Applications
- Azure – The Twelve-Factor Application
- GCP – Twelve-factor app development on Google Cloud
https://cloud.google.com/architecture/twelve-factor-app-development-on-gcp#3_configuration
If we continue to follow the guidelines, factor number 6 (processes) guides us to create stateless processes, meaning, separating the execution environment and the data, and keeping all stateful or permanent data in an external service such as a database or object storage.
For further reading, see:
- The Twelve-Factor App – Processes
https://12factor.net/processes
How do we migrate to immutable infrastructure?
Build a golden image
Follow the cloud vendor’s documentation about how to download the latest VM image or container image (from a container registry), update security patches, binaries, and libraries to the latest version, customize the image to suit the application’s needs, and store the image in a central image repository.
It is essential to copy/install only necessary components inside the image and remove any unnecessary components – it will allow you to keep a minimal image size and decrease the attack surface.
It is recommended to sign your image during the storage process in your private registry, to make sure it was not changed and that it was created by a known source.
For further reading, see:
- Automate OS Image Build Pipelines with EC2 Image Builder
https://aws.amazon.com/blogs/aws/automate-os-image-build-pipelines-with-ec2-image-builder/
- Creating a container image for use on Amazon ECS
https://docs.aws.amazon.com/AmazonECS/latest/userguide/create-container-image.html
- Azure VM Image Builder overview
https://learn.microsoft.com/en-us/azure/virtual-machines/image-builder-overview
- Build and deploy container images in the cloud with Azure Container Registry Tasks
https://learn.microsoft.com/en-us/azure/container-registry/container-registry-tutorial-quick-task
- Create custom images
https://cloud.google.com/compute/docs/images/create-custom
- Building container images
https://cloud.google.com/build/docs/building/build-containers
Create deployment pipeline
Create a CI/CD pipeline to automate the following process:
- Check for new software/binaries/library versions against well-known and signed repositories
- Pull the latest image from your private image repository
- Update the image with the latest software and configuration changes in your image registry
- Run automated tests (unit tests, functional tests, acceptance tests, integration tests) to make sure the new build does not break the application
- Gradually deploy a new version of your VMs / containers and decommission old versions
For further reading, see:
- Create an image pipeline using the EC2 Image Builder console wizard
https://docs.aws.amazon.com/imagebuilder/latest/userguide/start-build-image-pipeline.html
- Create a container image pipeline using the EC2 Image Builder console wizard
https://docs.aws.amazon.com/imagebuilder/latest/userguide/start-build-container-pipeline.html
- Streamline your custom image-building process with the Azure VM Image Builder service
- Build a container image to deploy apps using Azure Pipelines
https://learn.microsoft.com/en-us/azure/devops/pipelines/ecosystems/containers/build-image
- Creating the secure image pipeline
https://cloud.google.com/software-supply-chain-security/docs/create-secure-image-pipeline
- Using the secure image pipeline
https://cloud.google.com/software-supply-chain-security/docs/use-image-pipeline
Continues monitoring
Continuously monitor for compliance against your desired configuration settings, security best practices (such as CIS benchmark hardening settings), and well-known software vulnerabilities.
In case any of the above is met, create an automated process, and use your previously created pipeline to replace the currently running images with the latest image version from your registry.
For further reading, see:
- How to Set Up Continuous Golden AMI Vulnerability Assessments with Amazon Inspector
- Scanning Amazon ECR container images with Amazon Inspector
https://docs.aws.amazon.com/inspector/latest/user/enable-disable-scanning-ecr.html
- Manage virtual machine compliance
- Use Defender for Containers to scan your Azure Container Registry images for vulnerabilities
- Automatically scan container images for known vulnerabilities
https://cloud.google.com/kubernetes-engine/docs/how-to/security-posture-vulnerability-scanning
Summary
In this article, we have reviewed the concept of immutable infrastructure, its benefits, and the process for creating a secure, automated, and scalable solution for building immutable infrastructure in the cloud.
References
- The History of Pets vs Cattle and How to Use the Analogy Properly
https://cloudscaling.com/blog/cloud-computing/the-history-of-pets-vs-cattle/
- Deploy using immutable infrastructure
- Immutable infrastructure CI/CD using Jenkins and Terraform on Azure
- Automate your deployments
https://cloud.google.com/architecture/framework/operational-excellence/automate-your-deployments
Not all cloud providers are built the same

When organizations debate workload migration to the cloud, they begin to realize the number of public cloud alternatives that exist, both U.S hyper-scale cloud providers and several small to medium European and Asian providers.
The more we study the differences between the cloud providers (both IaaS/PaaS and SaaS providers), we begin to realize that not all cloud providers are built the same.
How can we select a mature cloud provider from all the alternatives?
Transparency
Mature cloud providers will make sure you don’t have to look around their website, to locate their security compliance documents, allow you to download their security controls documentation, such as SOC 2 Type II, CSA Star, CSA Cloud Controls Matrix (CCM), etc.
What happens if we wish to evaluate the cloud provider by ourselves?
Will the cloud provider (no matter what cloud service model), allow me to conduct a security assessment (or even a penetration test), to check the effectiveness of his security controls?
Global presence
When evaluating cloud providers, ask yourself the following questions:
- Does the cloud provider have a local presence near my customers?
- Will I be able to deploy my application in multiple countries around the world?
- In case of an outage, will I be able to continue serving my customers from a different location with minimal effort?
Scale
Deploying an application for the first time, we might not think about it, but what happens in the peak scenario?
Will the cloud provider allow me to deploy hundreds or even thousands of VM’s (or even better, containers), in a short amount of time, for a short period, from the same location?
Will the cloud provider allow me infinite scale to store my data in cloud storage, without having to guess or estimate the storage size?
Multi-tenancy
As customers, we expect our cloud providers to offer us a fully private environment.
We never want to hear about “noisy neighbor” (where one customer is using a lot of resources, which eventually affect other customers), and we never want to hear a provider admits that some or all of the resources (from VMs, database, storage, etc.) are being shared among customers.
Will the cloud provider be able to offer me a commitment to a multi-tenant environment?
Stability
One of the major reasons for migrating to the cloud is the ability to re-architect our services, whether we are still using VMs based on IaaS, databases based on PaaS, or fully managed CRM services based on SaaS.
In all scenarios, we would like to have a stable service with zero downtime.
Will the cloud provider allow me to deploy a service in a redundant architecture, that will survive data center outage or infrastructure availability issues (from authentication services, to compute, storage, or even network infrastructure) and return to business with minimal customer effect?
APIs
In the modern cloud era, everything is based on API (Application programming interface).
Will the cloud provider offer me various APIs?
From deploying an entire production environment in minutes using Infrastructure as Code, to monitoring both performances of our services, cost, and security auditing – everything should be allowed using API, otherwise, it is simply not scale/mature/automated/standard and prone to human mistakes.
Data protection
Encrypting data at transit, using TLS 1.2 is a common standard, but what about encryption at rest?
Will the cloud provider allow me to encrypt a database, object storage, or a simple NFS storage using my encryption keys, inside a secure key management service?
Will the cloud provider allow me to automatically rotate my encryption keys?
What happens if I need to store secrets (credentials, access keys, API keys, etc.)? Will the cloud provider allow me to store my secrets in a secured, managed, and audited location?
In case you are about to store extremely sensitive data (from PII, credit card details, healthcare data, or even military secrets), will the cloud provider offer me a solution for confidential computing, where I can store sensitive data, even in memory (or in use)?
Well architected
A mature cloud provider has a vast amount of expertise to share knowledge with you, about how to build an architecture that will be secure, reliable, performance efficient, cost-optimized, and continually improve the processes you have built.
Will the cloud provider offer me rich documentation on how to achieve all the above-mentioned goals, to provide your customers the best experience?
Will the cloud provider offer me an automated solution for deploying an entire application stack within minutes from a large marketplace?
Cost management
The more we broaden our use of the IaaS / PaaS service, the more we realize that almost every service has its price tag.
We might not prepare for this in advance, but once we begin to receive the monthly bill, we begin to see that we pay a lot of money, sometimes for services we don’t need, or for an expensive tier of a specific service.
Unlike on-premise, most cloud providers offer us a way to lower the monthly bill or pay for what we consume.
Regarding cost management, ask yourself the following questions:
Will the cloud provider charge me for services when I am not consuming them?
Will the cloud provider offer me detailed reports that will allow me to find out what am I paying for?
Will the cloud provider offer me documents and best practices for saving costs?
Summary
Answering the above questions with your preferred cloud provider, will allow you to differentiate a mature cloud provider, from the rest of the alternatives, and to assure you that you have made the right choice selecting a cloud provider.
The answers will provide you with confidence, both when working with a single cloud provider, and when taking a step forward and working in a multi-cloud environment.
References
Security, Trust, Assurance, and Risk (STAR)
https://cloudsecurityalliance.org/star/
SOC 2 – SOC for Service Organizations: Trust Services Criteria
https://www.aicpa.org/interestareas/frc/assuranceadvisoryservices/aicpasoc2report.html
Confidential Computing and the Public Cloud
https://eyal-estrin.medium.com/confidential-computing-and-the-public-cloud-fa4de863df3
Confidential computing: an AWS perspective
https://aws.amazon.com/blogs/security/confidential-computing-an-aws-perspective/
AWS Well-Architected
https://aws.amazon.com/architecture/well-architected
Azure Well-Architected Framework
https://docs.microsoft.com/en-us/azure/architecture/framework/
Google Cloud’s Architecture Framework
https://cloud.google.com/architecture/framework
Oracle Architecture Center
https://docs.oracle.com/solutions/
Alibaba Cloud’s Well-Architectured Framework
Modern cloud deployment and usage
When migrating existing environments to the cloud, or even when building and deploying new environments in the cloud, there are many alternatives. There is no one right or wrong way.
In this post we will review the way it was done in the past (AKA “old school”) and review the more modern options for environment deployments.
Traditional deployment
Traditionally, when we had to deploy a new dev/test or a production environment for a new service or application, we usually considered 3 tier applications. These built from a presentation layer (such as web server or full client deployment), a business logic (such as application server) and a back-end storage tier (such as database server).
Since each layer (or tier) depended on the rest of the layers, each software upgrade or addition of another server (for high availability) required downtime for the entire application or service. The result: a monolith.
This process was cumbersome. It took several weeks to deploy the operating system, deploy the software, configure it, conduct tests, get approval from the business customer, take the same process to deploy a production environment and finally switch to production.
This process was viable for small scale deployments, or simple applications, serving a small number of customers.
We usually focus more on the system side of the deployment, perhaps a single server containing all the components. Until we reach the hardware limitations (CPU / Memory / Storage / Network limitations) before we begin to scale up (switching to newer hardware with more CPU / Memory / Storage / faster network interface card). Only then may we find out this solution does not scale enough to serve customers in the long run.
When replacing the VM size does not solve bottlenecks, we begin scale out by adding more servers (such as more web servers, cluster of database servers, etc.). Then we face new kind of problems, when we need to take the entire monolith down, every time we plan to deploy security patches, deploy software upgrades, etc.
Migrating existing architecture to the public cloud (AKA “lift and shift”) is a viable option, and it has its own pros and cons:
Pros:
· We keep our current deployment method
· Less knowledge is required from the IT team
· We shorten the time it takes to deploy new environments
· We will probably be able to keep our investment in licenses (AKA “Bring your own license”)
· We will probably be able to reuse our existing backup, monitoring and software deployment tools we used in the on-premises deployment.
Cons:
· Using the most common purchase model “on demand” or “pay as you go” is suitable for unknown usage patterns (such as development or test environment) but soon it will become expensive to use this purchase model on production environments, running 24×7 (even when using hourly based purchase model), as compared to purchase hardware for the on-premises, and using the hardware without a time limitation (until the hardware support ends)
· We are still in-charge of operating system maintenance (upgrades, backup, monitoring, various agent deployment, etc.) — the larger our server farm is, the bigger the burden we have on maintenance, until it does not scale enough, and we need larger IT departments, and we lower the value we bring to our organization.
Deployment in the modern world
Modern development and application deployment, also known as “Cloud Native applications”, focus on service (instead of servers with applications). It leverages the benefits of the cloud’s built-in capabilities and features:
Scale — We build our services to be able to serve millions of customers (instead of several hundred).
Elasticity — Our applications are aware of load and can expand or shrink resources in accordance with needs.
High availability — Instead of exposing a single server in a single data center to the Internet, we deploy our compute resources (VMs, containers, etc.) behind a managed load-balancer service, and we spread the server deployment between several availability zones (usually an availability zone equals a data center). This allows us to automatically monitor the server’s availability and deploy new compute resources when one server fails or when we need more compute resources due to server load. Since the cloud offers managed services (from load-balancers, NAT gateways, VPN tunnel, object storage, managed databases, etc.) we benefit from cloud providers’ SLAs, which are extremely difficult to get in traditional data centers.
Observability — In the past we used to monitor basic metrics such as CPU or memory load, free disk space (or maybe percentage of read/write events). Today, we add more and more metrics for the applications themselves, such as number of concurrent users, time it takes to query the database, percentage of errors in the web server log file, communication between components, etc. This allows us to predict service failures before our customers observe them.
Security — Managing and maintaining large fleets of servers in the traditional data center requires a huge amount of work (security patches, firewall rules, DDoS protection, configuration management, encryption at transit and at rest, auditing, etc.). In the cloud, we benefit from built-in security capabilities, all working together and accessible both manually (for small scale environments) and automatically (as part of Infrastructure as a Code tools and languages).
Containers and Kubernetes to the rescue
The use of microservice architecture revolutionized the way we develop and deploy modern applications by breaking previously complex architecture into smaller components and dividing them by the task they serve in our application or service.
This is where containers come into the picture. Instead of deploying virtual machines, with full operating system and entire software stacks, we use containers. This allows us to wrap the minimum number of binaries, libraries, and code, required for a specific task (login to the application, running the business logic, ingesting data into an object store or directly into the back-end database, running reporting model, etc.)
Containers enable better utilization of the existing “hardware” by deploying multiple containers (each can be for different service) on the same virtual hardware (or bare metal) and reach near 100% of resource utilization.
Containers allow small development teams to focus on specific tasks or components, almost separately from the rest of the development teams (components still needs to communicate between each other). They can upgrade lines of code, scale in and out according to load, and hopefully one day be able to switch between cloud providers (AKA be “Cloud agnostic”).
Kubernetes, is the de-facto orchestrator for running containers. It can deploy containers according to needs (such as load), monitor the status of each running container (and deploy a new container to replace of non-functioning container), automatically upgrade software build (by deploying containers that contain new versions of code), make certain containers are being deployed equally between virtual servers (for load and high availability), etc.
Pros:
· Decreases number of binaries and libraries, minimal for running the service
· Can be developed locally on a laptop, and run-in large scale in the cloud (solves the problem of “it runs on my machine”)
· Cloud vendor agnostic (unless you consume services from the cloud vendor’s ecosystem)
Cons:
· Takes time to learn how to wrap and maintain
· Challenging to debug
· A large percentage of containers available are outdated and contain security vulnerabilities.
Serverless / Function as a service
These are new modern ways to deploy applications in a more cost-effective manner, when we can take small portions of our code (AKA “functions”) for doing specific tasks and deploy them inside a managed compute environment (AKA “serverless”) and pay for the number of resources we consume (CPU / Memory) and the time (in seconds) it takes to run a function.
Serverless can be fitted inside microservice architecture by replacing tasks that we used to put inside containers.
Suitable for stateless functions (for example: no need to keep caching of data) or for scenarios where we have specific tasks. For example, when we need to invoke a function as result of an event, like closing a port in a security group, or because of an event triggered in a security monitoring service.
Pros:
· No need to maintain the underlying infrastructure (compute resources, OS, patching, etc.)
· Scales automatically according to load
· Extremely inexpensive in small scale (compared to a container)
Cons:
· Limited to maximum of 15 minutes of execution time
· Limited function storage size
· Challenging to debug due to the fact that it is a closed environment (no OS access)
· Might be expensive in large scale (compared to a container)
· Limited number of supported development languages
· Long function starts up time (“Warm up”)
Summary
The world of cloud deployment is changing. And this is good news.
Instead of server fleets and a focus on the infrastructure that might not be suitable or cost-effective for our applications, modern cloud deployment is focused on bringing value to our customers and to our organizations by shortening the time it takes to develop new capabilities (AKA “Time to market”). It allows us to experiment, make mistakes and recover quickly (AKA “fail safe”), while making better use of resources (pay for what we consume), being able to predict outages and downtime in advance.
The Future of Data Security Lies in the Cloud

We have recently read a lot of posts about the SolarWinds hack, a vulnerability in a popular monitoring software used by many organizations around the world.
This is a good example of supply chain attack, which can happen to any organization.
We have seen similar scenarios over the past decade, from the Heartbleed bug, Meltdown and Spectre, Apache Struts, and more.
Organizations all around the world were affected by the SolarWinds hack, including the cybersecurity company FireEye, and Microsoft.
Events like these make organizations rethink their cybersecurity and data protection strategies and ask important questions.
Recent changes in the European data protection laws and regulations (such as Schrems II) are trying to limit data transfer between Europe and the US.
Should such security breaches occur? Absolutely not.
Should we live with the fact that such large organization been breached? Absolutely not!
Should organizations, who already invested a lot of resources in cloud migration move back workloads to on-premises? I don’t think so.
But no organization, not even major financial organizations like banks or insurance companies, or even the largest multinational enterprises, have enough manpower, knowledge, and budget to invest in proper protection of their own data or their customers’ data, as hyperscale cloud providers.
There are several of reasons for this:
- Hyperscale cloud providers invest billions of dollars improving security controls, including dedicated and highly trained personnel.
- Breach of customers’ data that resides at hyperscale cloud providers can drive a cloud provider out of business, due to breach of customer’s trust.
- Security is important to most organizations; however, it is not their main line of expertise.
Organization need to focus on their core business that brings them value, like manufacturing, banking, healthcare, education, etc., and rethink how to obtain services that support their business goals, such as IT services, but do not add direct value.
Recommendations for managing security
Security Monitoring
Security best practices often state: “document everything”.
There are two downsides to this recommendation: One, storage capacity is limited and two, most organizations do not have enough trained manpower to review the logs and find the top incidents to handle.
Switching security monitoring to cloud-based managed systems such as Azure Sentinel or Amazon GuardDuty, will assist in detecting important incidents and internally handle huge logs.
Encryption
Another security best practice state: “encrypt everything”.
A few years ago, encryption was quite a challenge. Will the service/application support the encryption? Where do we store the encryption key? How do we manage key rotation?
In the past, only banks could afford HSM (Hardware Security Module) for storing encryption keys, due to the high cost.
Today, encryption is standard for most cloud services, such as AWS KMS, Azure Key Vault, Google Cloud KMS and Oracle Key Management.
Most cloud providers, not only support encryption at rest, but also support customer managed key, which allows the customer to generate his own encryption key for each service, instead of using the cloud provider’s generated encryption key.
Security Compliance
Most organizations struggle to handle security compliance over large environments on premise, not to mention large IaaS environments.
This issue can be solved by using managed compliance services such as AWS Security Hub, Azure Security Center, Google Security Command Center or Oracle Cloud Access Security Broker (CASB).
DDoS Protection
Any organization exposing services to the Internet (from publicly facing website, through email or DNS service, till VPN service), will eventually suffer from volumetric denial of service.
Only large ISPs have enough bandwidth to handle such an attack before the border gateway (firewall, external router, etc.) will crash or stop handling incoming traffic.
The hyperscale cloud providers have infrastructure that can handle DDoS attacks against their customers, services such as AWS Shield, Azure DDoS Protection, Google Cloud Armor or Oracle Layer 7 DDoS Mitigation.
Using SaaS Applications
In the past, organizations had to maintain their entire infrastructure, from messaging systems, CRM, ERP, etc.
They had to think about scale, resilience, security, and more.
Most breaches of cloud environments originate from misconfigurations at the customers’ side on IaaS / PaaS services.
Today, the preferred way is to consume managed services in SaaS form.
These are a few examples: Microsoft Office 365, Google Workspace (Formerly Google G Suite), Salesforce Sales Cloud, Oracle ERP Cloud, SAP HANA, etc.
Limit the Blast Radius
To limit the “blast radius” where an outage or security breach on one service affects other services, we need to re-architect infrastructure.
Switching from applications deployed inside virtual servers to modern development such as microservices based on containers, or building new applications based on serverless (or function as a service) will assist organizations limit the attack surface and possible future breaches.
Example of these services: Amazon ECS, Amazon EKS, Azure Kubernetes Service, Google Kubernetes Engine, Google Anthos, Oracle Container Engine for Kubernetes, AWS Lambda, Azure Functions, Google Cloud Functions, Google Cloud Run, Oracle Cloud Functions, etc.
Summary
The bottom line: organizations can increase their security posture, by using the public cloud to better protect their data, use the expertise of cloud providers, and invest their time in their core business to maximize value.
Security breaches are inevitable. Shifting to cloud services does not shift an organization’s responsibility to secure their data. It simply does it better.