Archive for the ‘Google’ Category
Checklist for designing cloud-native applications – Part 2: Security aspects

This post was originally published by the Cloud Security Alliance.
In Chapter 1 of this series about considerations when building cloud-native applications, we introduced various topics such as business requirements, infrastructure considerations, automation, resiliency, and more.
In this chapter, we will review security considerations when building cloud-native applications.
IAM Considerations – Authentication
Identity and Access Management plays a crucial role when designing new applications.
We need to ask ourselves – Who are our customers?
If we are building an application that will serve internal customers, we need to make sure our application will be able to sync identities from our identity provider (IdP).
On the other hand, if we are planning an application that will serve external customers, in most cases we would not want to manage the identities themselves, but rather allow authentication based on SAML, OAuth, or OpenID connect, and manage the authorization in our application.
Examples of managed cloud-native identity services: AWS IAM Identity Center, Microsoft Entra ID, and Google Cloud Identity.
IAM Considerations – Authorization
Authorization is also an important factor when designing applications.
When our application consumes services (such as compute, storage, database, etc.) from a CSP ecosystem, each CSP has its mechanisms to manage permissions to access services and take actions, and each CSP has its way of implementing Role-based access control (RBAC).
Regardless of the built-in mechanisms to consume cloud infrastructure, we must always follow the principle of least privilege (i.e., minimal permissions to achieve a task).
On the application layer, we need to design an authorization mechanism to check each identity that was authenticated to our application, against an authorization engine (interactive authentication, non-interactive authentication, or even API-based access).
Although it is possible to manage authorization using our own developed RBAC mechanism, it is time to consider more cloud-agnostic authorization policy engines such as Open Policy Agent (OPA).
One of the major benefits of using OPA is the fact that its policy engine is not limited to authorization to an application – you can also use it for Kubernetes authorization, for Linux (using PAM), and more.
Policy-as-Code Considerations
Policy-as-Code allows you to configure guardrails on various aspects of your workload.
Guardrails are offered by all major cloud providers, outside the boundary of a cloud account, and impact the maximum allowed resource consumption or configuration.
Examples of guardrails:
- Limitation on the allowed region for deploying resources (compute, storage, database, network, etc.)
- Enforce encryption at rest
- Forbid the ability to create publicly accessible resources (such as a VM with public IP)
- Enforce the use of specific VM instance size (number of CPUs and memory allowed)
Guardrails can also be enforced as part of a CI/CD pipeline when deploying resources using Infrastructure as Code for automation purposes – The IaC code is been evaluated before the actual deployment phase, and assuming the IaC code does not violate the Policy as Code, resources are been updated.
Examples of Policy-as-Code: AWS Service control policies (SCPs), Azure Policy, Google Organization Policy Service, HashiCorp Sentinel, and Open Policy Agent (OPA).
Data Protection Considerations
Almost any application contains valuable data, whether the data has business or personal value, and as such we must protect the data from unauthorized parties.
A common way to protect data is to store it in encrypted form:
- Encryption in transit – done using protocols such as TLS (where the latest supported version is 1.3)
- Encryption at rest – done on a volume, disk, storage, or database level, using algorithms such as AES
- Encryption in use – done using hardware supporting a trusted execution environment (TEE), also referred to as confidential computing
When encrypting data we need to deal with key generation, secured vault for key storage, key retrieval, and key destruction.
All major CSPs have their key management service to handle the entire key lifecycle.
If your application is deployed on top of a single CSP infrastructure, prefer to use managed services offered by the CSP.
For encryption in use, select services (such as VM instances or Kubernetes worker nodes) that support confidential computing.
Secrets Management Considerations
Secrets are equivalent to static credentials, allowing access to services and resources.
Examples of secrets are API keys, passwords, database credentials, etc.
Secrets, similarly to encryption keys, are sensitive and need to be protected from unauthorized parties.
From the initial application design process, we need to decide on a secured location to store secrets.
All major CSPs have their own secrets management service to handle the entire secret’s lifecycle.
As part of a CI/CD pipeline, we should embed an automated scanning process to detect secrets embedded as part of code, scripts, and configuration files, to avoid storing any secrets as part of our application (i.e., outside the secured secrets management vault).
Examples of secrets management services: AWS Secrets Manager, Azure Key Vault, Google Secret Manager, and HashiCorp Vault.
Network Security Considerations
Applications must be protected at the network layer, whether we expose our application to internal customers or customers over the public internet.
The fundamental way to protect infrastructure at the network layer is using access controls, which are equivalent to layer 3/layer 4 firewalls.
All CSPs have access control mechanisms to restrict access to services (from access to VMs, databases, etc.)
Examples of Layer 3 / Layer 4 managed services: AWS Security groups, Azure Network security groups, and Google VPC firewall rules.
Some cloud providers support private access to their services, by adding a network load-balancer in front of various services, with an internal IP from the customer’s private subnet, enforcing all traffic to pass inside the CSP’s backbone, and not over the public internet.
Examples of private connectivity solutions: AWS PrivateLink, Azure Private Link, and Google VPC Service Controls.
Some of the CSPs offer managed layer 7 firewalls, allowing customers to enforce traffic based on protocols (and not ports), inspecting TLS traffic for malicious content, and more, in case your application or business requires those capabilities.
Examples of Layer 7 managed firewalls: AWS Network Firewall, Azure Firewall, and Google Cloud NGFW.
Application Layer Protection Considerations
Any application accessible to customers (internal or over the public Internet), is exposed to application layer attacks.
Attacks can range from malicious code injection, data exfiltration (or data leakage), data tampering, unauthorized access, and more.
Whether you are exposing an API, a web application, or a mobile application, it is important to implement application layer protection, such as a WAF service.
All major CSPs offer managed WAF services, and there are many SaaS solutions by commercial vendors that offer managed WAF services.
Examples of managed WAF services: AWS WAF, Azure WAF, and Google Cloud Armor.
DDoS Protection Considerations
Denial-of-Service (DoS) or Distributed Denial-of-Service (DDoS) is a risk for any service accessible over the public Internet.
Such attacks try to consume all the available resources (from network bandwidth to CPU/memory), directly impacting the service availability to be accessible by customers.
All major CSPs offer managed DDoS protection services, and there are many DDoS protection solutions by commercial vendors that offer managed DDoS protection services.
Examples of managed DDoS protection services: AWS Shield, Azure DDoS Protection, Google Cloud Armor, and Cloudflare DDoS protection.
Patch Management Considerations
Software tends to be vulnerable, and as such it must be regularly patched.
For applications deployed on top of virtual machines:
- Create a “golden image” of a virtual machine, and regularly update the image with the latest security patches and software updates.
- For applications deployed on top of VMs, create a regular patch update process.
For applications wrapped inside containers, create a “golden image” of each of the application components, and regularly update the image with the latest security patches and software updates.
Embed software composition analysis (SCA) tools to scan and detect vulnerable third-party components – in case vulnerable components (or their dependencies) are detected, begin a process of replacing the vulnerable components.
Examples of patch management solutions: AWS Systems Manager Patch Manager, Azure Update Manager, and Google VM Manager Patch.
Compliance Considerations
Compliance is an important security factor when designing an application.
Some applications contain personally identifiable information (PII) about employees or customers, which requires compliance against privacy and data residency laws and regulations (such as the GDPR in Europe, the CPRA in California, the LGPD in Brazil, etc.)
Some organizations decide to be compliant with industry or security best practices, such as the Center for Internet Security (CIS) Benchmark for hardening infrastructure components, and can be later evaluated using compliance services or Cloud security posture management (CSPM) solutions.
References for compliance: AWS Compliance Center, Azure Service Trust Portal, and Google Compliance Resource Center.
Incident Response
When designing an application in the cloud, it is important to be prepared to respond to security incidents:
- Enable logging from both infrastructure and application components, and stream all logs to a central log aggregator. Make sure logs are stored in a central, immutable location, with access privileges limited for the SOC team.
- Select a tool to be able to review logs, detect anomalies, and be able to create actionable insights for the SOC team.
- Create playbooks for the SOC team, to know how to respond in case of a security incident (how to investigate, where to look for data, who to notify, etc.)
- To be prepared for a catastrophic event (such as a network breach, or ransomware), create automated solutions, to allow you to quarantine the impacted services, and deploy a new environment from scratch.
References for incident response documentation: AWS Security Incident Response Guide, Azure Incident response, and Google Data incident response process.
Summary
In the second blog post in this series, we talked about many security-related aspects, that organizations should consider when designing new applications in the cloud.
In this part of the series, we have reviewed various aspects, from identity and access management to data protection, network security, patch management, compliance, and more.
It is highly recommended to use the topics discussed in this series of blog posts, as a baseline when designing new applications in the cloud, and continuously improve this checklist of considerations when documenting your projects.
About the Author
Eyal Estrin is a cloud and information security architect, and the author of the book Cloud Security Handbook, with more than 20 years in the IT industry. You can connect with him on Twitter.
Opinions are his own and not the views of his employer.
Building Resilient Applications in the Cloud

When building an application for serving customers, one of the questions raised is how do I know if my application is resilient and will survive a failure?
In this blog post, we will review what it means to build resilient applications in the cloud, and we will review some of the common best practices for achieving resilient applications.
What does it mean resilient applications?
AWS provides us with the following definition for the term resiliency:
“The ability of a workload to recover from infrastructure or service disruptions, dynamically acquire computing resources to meet demand, and mitigate disruptions, such as misconfigurations or transient network issues.”
Resiliency is part of the Reliability pillar for cloud providers such as AWS, Azure, GCP, and Oracle Cloud.
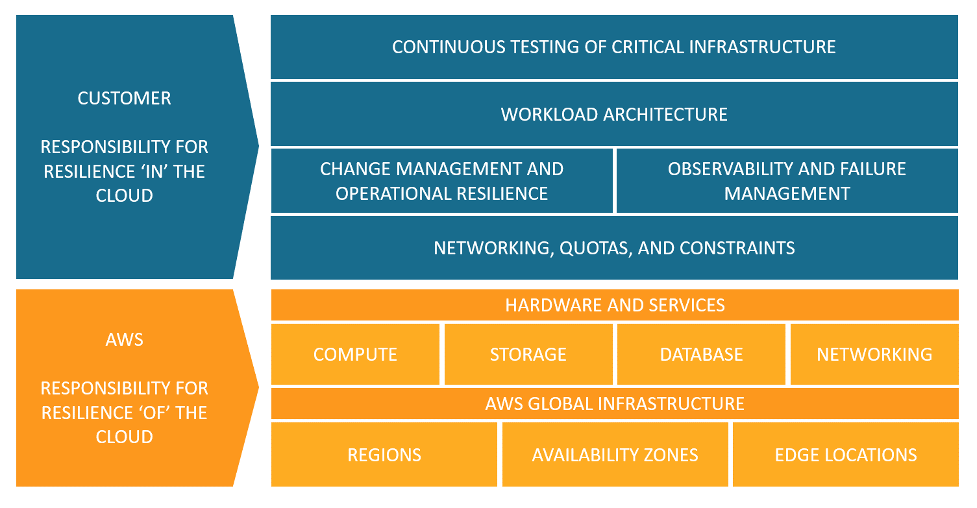
AWS takes it one step further, and shows how resiliency is part of the shared responsibility model:
- The cloud provider is responsible for the resilience of the cloud (i.e., hardware, software, computing, storage, networking, and anything related to their data centers)
- The customer is responsible for the resilience in the cloud (i.e., selecting the services to use, building resilient architectures, backup strategies, data replication, and more).
How do we build resilient applications?
This blog post assumes that you are building modern applications in the public cloud.
We have all heard of RTO (Recovery time objective).
Resilient workload (a combination of application, data, and the infrastructure that supports it), should not only recover automatically, but it must recover within a pre-defined RTO, agreed by the business owner.
Below are common best practices for building resilient applications:
Design for high-availability
The public cloud allows you to easily deploy infrastructure over multiple availability zones.
Examples of implementing high availability in the cloud:
- Deploying multiple VMs behind an auto-scaling group and a front-end load-balancer
- Spreading container load over multiple Kubernetes worker nodes, deploying in multiple AZs
- Deploying a cluster of database instances in multiple AZs
- Deploying global (or multi-regional) database services (such as Amazon Aurora Global Database, Azure Cosmos DB, Google Cloud Spanner, and Oracle Global Data Services (GDS)
- Configure DNS routing rules to send customers’ traffic to more than a single region
- Deploy global load-balancer (such as AWS Global Accelerator, Azure Cross-region Load Balancer, or Google Global external Application Load Balancer) to spread customers’ traffic across regions
Implement autoscaling
Autoscaling is one of the biggest advantages of the public cloud.
Assuming we built a stateless application, we can add or remove additional compute nodes using autoscaling capability, and adjust it to the actual load on our application.
In a cloud-native infrastructure, we will use a managed load-balancer service, to receive traffic from customers, and send an API call to an autoscaling group, to add or remove additional compute nodes.
Implement microservice architecture
Microservice architecture is meant to break a complex application into smaller parts, each responsible for certain functionality of the application.
By implementing microservice architecture, we are decreasing the impact of failed components on the rest of the application.
In case of high load on a specific component, it is possible to add more compute resources to the specific component, and in case we discover a bug in one of the microservices, we can roll back to a previous functioning version of the specific microservice, with minimal impact on the rest of the application.
Implement event-driven architecture
Event-driven architecture allows us to decouple our application components.
Resiliency can be achieved using event-driven architecture, by the fact that even if one component fails, the rest of the application continues to function.
Components are loosely coupled by using events that trigger actions.
Event-driven architectures are usually (but not always) based on services managed by cloud providers, who are responsible for the scale and maintenance of the managed infrastructure.
Event-driven architectures are based on models such as pub/sub model (services such as Amazon SQS, Azure Web PubSub, Google Cloud Pub/Sub, and OCI Queue service) or based on event delivery (services such as Amazon EventBridge, Azure Event Grid, Google Eventarc, and OCI Events service).
Implement API Gateways
If your application exposes APIs, use API Gateways (services such as Amazon API Gateway, Azure API Management, Google Apigee, or OCI API Gateway) to allow incoming traffic to your backend APIs, perform throttling to protect the APIs from spikes in traffic, and perform authorization on incoming requests from customers.
Implement immutable infrastructure
Immutable infrastructure (such as VMs or containers) are meant to run application components, without storing session information inside the compute nodes.
In case of a failed component, it is easy to replace the failed component with a new one, with minimal disruption to the entire application, allowing to achieve fast recovery.
Data Management
Find the most suitable data store for your workload.
A microservice architecture allows you to select different data stores (from object storage to backend databases) for each microservice, decreasing the risk of complete failure due to availability issues in one of the backend data stores.
Once you select a data store, replicate it across multiple AZs, and if the business requires it, replicate it across multiple regions, to allow better availability, closer to the customers.
Implement observability
By monitoring all workload components, and sending logs from both infrastructure and application components to a central logging system, it is possible to identify anomalies, anticipate failures before they impact customers, and act.
Examples of actions can be sending a command to restart a VM, deploying a new container instead of a failed one, and more.
It is important to keep track of measurements — for example, what is considered normal response time to a customer request, to be able to detect anomalies.
Implement chaos engineering
The base assumption is that everything will eventually fail.
Implementing chaos engineering, allows us to conduct controlled experiments, inject faults into our workloads, testing what will happen in case of failure.
This allows us to better understand if our workload will survive a failure.
Examples can be adding load on disk volumes, injecting timeout when an application tier connects to a backend database, and more.
Examples of services for implementing chaos engineering are AWS Fault Injection Simulator, Azure Chaos Studio, and Gremlin.
Create a failover plan
In an ideal world, your workload will be designed for self-healing, meaning, it will automatically detect a failure and recover from it, for example, replace failed components, restart services, or switch to another AZ or even another region.
In practice, you need to prepare a failover plan, keep it up to date, and make sure your team is trained to act in case of major failure.
A disaster recovery plan without proper and regular testing is worth nothing — your team must practice repeatedly, and adjust the plan, and hopefully, they will be able to execute the plan during an emergency with minimal impact on customers.
Resilient applications tradeoffs
Failure can happen in various ways, and when we design our workload, we need to limit the blast radius on our workload.
Below are some common failure scenarios, and possible solutions:
- Failure in a specific component of the application — By designing a microservice architecture, we can limit the impact of a failed component to a specific area of our application (depending on the criticality of the component, as part of the entire application)
- Failure or a single AZ — By deploying infrastructure over multiple AZs, we can decrease the chance of application failure and impact on our customers
- Failure of an entire region — Although this scenario is rare, cloud regions also fail, and by designing a multi-region architecture, we can decrease the impact on our customers
- DDoS attack — By implementing DDoS protection mechanisms, we can decrease the risk of impacting our application with a DDoS attack
Whatever solution we design for our workloads, we need to understand that there is a cost and there might be tradeoffs for the solution we design.
Multi-region architecture aspects
A multi-region architecture will allow the most highly available resilient solution for your workloads; however, multi-region adds high cost for cross-region egress traffic, most services are limited to a single region, and your staff needs to know to support such a complex architecture.
Another limitation of multi-region architecture is data residency — if your business or regulator demands that customers’ data be stored in a specific region, a multi-region architecture is not an option.
Service quota/service limits
When designing a highly resilient architecture, we must take into consideration service quotas or service limits.
Sometimes we are bound to a service quota on a specific AZ or region, an issue that we may need to resolve with the cloud provider’s support team.
Sometimes we need to understand there is a service limit in a specific region, such as a specific service that is not available in a specific region, or there is a shortage of hardware in a specific region.
Autoscaling considerations
Horizontal autoscale (the ability to add or remove compute nodes) is one of the fundamental capabilities of the cloud, however, it has its limitations.
Provisioning a new compute node (from a VM, container instance, or even database instance) may take a couple of minutes to spin up (which may impact customer experience) or to spin down (which may impact service cost).
Also, to support horizontal scaling, you need to make sure the compute nodes are stateless, and that the application supports such capability.
Failover considerations
One of the limitations of database failover is their ability to switch between the primary node and one of the secondary nodes, either in case of failure or in case of scheduled maintenance.
We need to take into consideration the data replication, making sure transactions were saved and moved from the primary to the read replica node.
Summary
In this blog post, we have covered many aspects of building resilient applications in the cloud.
When designing new applications, we need to understand the business expectations (in terms of application availability and customer impact).
We also need to understand the various architectural design considerations, and their tradeoffs, to be able to match the technology to the business requirements.
As I always recommend — do not stay on the theoretical side of the equation, begin designing and building modern and highly resilient applications to serve your customers — There is no replacement for actual hands-on experience.
References
- Understand resiliency patterns and trade-offs to architect efficiently in the cloud
- Building resilience to your business requirements with Azure
- Success through culture: why embracing failure encourages better software delivery
- Building Resilient Solutions in OCI
About the Author
Eyal Estrin is a cloud and information security architect, and the author of the book Cloud Security Handbook, with more than 20 years in the IT industry. You can connect with him on Twitter.
Opinions are his own and not the views of his employer.
Why choosing “Lift & Shift” is a bad migration strategy

One of the first decisions organizations make before migrating applications to the public cloud is deciding on a migration strategy.
For many years, the most common and easy way to migrate applications to the cloud was choosing a rehosting strategy, also known as “Lift and shift”.
In this blog post, I will review some of the reasons, showing that strategically this is a bad decision.
Introduction
When reviewing the landscape of possibilities for migrating legacy or traditional applications to the public cloud, rehosting is the best option as a short-term solution.
Taking an existing monolith application, and migrating it as-is to the cloud, is supposed to be an easy task:
- Map all the workload components (hardware requirements, operating system, software and licenses, backend database, etc.)
- Choose similar hardware (memory/CPU/disk space) to deploy a new VM instance(s)
- Configure network settings (including firewall rules, load-balance configuration, DNS, etc.)
- Install all the required software components (assuming no license dependencies exist)
- Restore the backend database from the latest full backup
- Test the newly deployed application in the cloud
- Expose the application to customers
From a time and required-knowledge perspective, this is considered a quick-win solution, but how efficient is it?
Cost-benefit
Using physical or even virtual machines does not guarantee us close to 100% of hardware utilization.
In the past organizations used to purchase hardware, and had to commit to 3–5 years (for vendor support purposes).
Although organizations could use the hardware 24×7, there were many cases where purchased hardware was consuming electricity and floor-space, without running at full capacity (i.e., underutilized).
Virtualization did allow organizations to run multiple VMs on the same physical hardware, but even then, it did not guarantee 100% hardware utilization — think about Dev/Test environments or applications that were not getting traffic from customers during off-peak hours.
The cloud offers organizations new purchase/usage methods (such as on-demand or Spot), allowing customers to pay just for the time they used compute resources.
Keeping a traditional data-center mindset, using virtual machines, is not efficient enough.
Switching to modern ways of running applications, such as the use of containers, Function-as-a-Service (FaaS), or event-driven architectures, allows organizations to make better use of their resources, at much better prices.
Right-sizing
On day 1, it is hard to predict the right VM instance size for the application.
When migrating applications as-is, organizations tend to select similar hardware (mostly CPU/Memory), to what they used to have in the traditional data center, regardless of the application’s actual usage.
After a legacy application is running for several weeks in the cloud, we can measure its actual performance, and switch to a more suitable VM instance size, gaining better utilization and price.
Tools such as AWS Compute Optimizer, Azure Advisor, or Google Recommender will allow you to select the most suitable VM instance size, but the VM still does not utilize 100% of the possible compute resources, compared to containers or Function-as-a-Service.
Scaling
Horizontal scaling is one of the main benefits of the public cloud.
Although it is possible to configure multiple VMs behind a load-balancer, with autoscaling capability, allowing adding or removing VMs according to the load on the application, legacy applications may not always support horizontal scaling, and even if they do support scale out (add more compute nodes), there is a very good chance they do not support scale in (removing unneeded compute nodes).
VMs do not support the ability to scale to zero — i.e., removing completely all compute nodes, when there is no customer demand.
Cloud-native applications deployed on top of containers, using a scheduler such as Kubernetes (such as Amazon EKS, Azure AKS, or Google GKE), can horizontally scale according to need (scale out as much as needed, or as many compute resources the cloud provider’s quota allows).
Functions as part of FaaS (such as AWS Lambda, Azure Functions, or Google Cloud Functions) are invoked as a result of triggers, and erased when the function’s job completes — maximum compute utilization.
Load time
Spinning up a new VM as part of auto-scaling activity (such as AWS EC2 Auto Scaling, Azure Virtual Machine Scale Sets, or Google Managed instance groups), upgrade, or reboot takes a long time — specifically for large workloads such as Windows VMs, databases (deployed on top of VM’s) or application servers.
Provisioning a new container (based on Linux OS), including all the applications and layers, takes a couple of seconds (depending on the number of software layers).
Invoking a new function takes a few seconds, even if you take into consideration cold start issues when downloading the function’s code.
Software maintenance
Every workload requires ongoing maintenance — from code upgrades, third-party software upgrades, and let us not forget security upgrades.
All software upgrade requires a lot of overhead from the IT, development, and security teams.
Performing upgrades of a monolith, where various components and services are tightly coupled together increases the complexity and the chances that something will break.
Switching to a microservice architecture, allows organizations to upgrade specific components (for example scale out, upgrade new version of code, new third-party software component), with small to zero impact on other components of the entire application.
Infrastructure maintenance
In the traditional data center, organizations used to deploy and maintain every component of the underlying infrastructure supporting the application.
Maintaining services such as databases or even storage arrays requires a dedicated trained staff, and requires a lot of ongoing efforts (from patching, backup, resiliency, high availability, and more).
In cloud-native environments, organizations can take advantage of managed services, from managed databases, storage services, caching, monitoring, and AI/ML services, without having to maintain the underlying infrastructure.
Unless an application relies on a legacy database engine, most of the chance, you will be able to replace a self-maintained database server, with a managed database service.
For storage services, most cloud providers already offer all the commodity storage services (from a managed NFS, SMB/CIFS, NetApp, and up to parallel file system for HPC workloads).
Most modern cloud-native services, use object storage services (such as Amazon S3, Azure Blob Storage, or Google Filestore), allowing scalable file systems for storing large amounts of data (from backups, and log files to data lake).
Most cloud providers offer managed networking services for load-balancing, firewalls, web application firewalls, and DDoS protection mechanisms, supporting workloads with unpredictable traffic.
SaaS services
Up until now, we mentioned lift & shift from the on-premise to VMs (mostly IaaS) and managed services (PaaS), but let us not forget there is another migration strategy — repurchasing, meaning, migrating an existing application, or selecting a managed platform such as Software-as-a-Service, allowing organizations to consume fully managed services, without having to take care of the on-going maintenance and resiliency.
Summary
Keeping a static data center mindset, and migrating using “lift & shift” to the public cloud, is the least cost-effective strategy and in most chances will end up with medium to low performance for your applications.
It may have been the common strategy a couple of years ago when organizations just began taking their first step in the public cloud, but as more knowledge is gained from both public cloud providers and all sizes of organizations, it is time to think about more mature cloud migration strategies.
It is time for organizations to embrace a dynamic mindset of cloud-native services and cloud-native applications, which provide organizations many benefits, from (almost) infinite scale, automated provisioning (using Infrastructure-as-Code), rich cloud ecosystem (with many managed services), and (if managed correctly) the ability to suit the workload costs to the actual consumption.
I encourage all organizations to expand their knowledge about the public cloud, assess their existing applications and infrastructure, and begin modernizing their existing applications.
Re-architecture may demand a lot of resources (both cost and manpower) in the short term but will provide an organization with a lot of benefits in the long run.
References:
- 6 Strategies for Migrating Applications to the Cloud
- Overview of application migration examples for Azure
- Migrate to Google Cloud
About the Author
Eyal Estrin is a cloud and information security architect, and the author of the book Cloud Security Handbook, with more than 20 years in the IT industry. You can connect with him on Twitter.
Opinions are his own and not the views of his employer.
Securing the software supply chain in the cloud

The software supply chain is considered one of the common threats in today’s modern cloud-native development, which poses a high risk to any organization.
It is about consuming software packages, source code, or even APIs from a third-party or untrusted source.
The last thing we wish to do is to block developers from building new applications, but we need to understand the threats to the software supply chain.
What are the common threats?
There are a couple of common threats that can arise from a software supply chain attack:
- Ransomware – An example is the NotPetya malware and Maersk
- Data breach – An example is the Okta Hack
- Backdoor – An example is the SolarWinds backdoor
- Access to private data – An example is the GitHub OAuth tokens attack
- API vulnerabilities – An example is the BOLA (Broken Object Level Authorization)
As we can see, most supply chain attacks begin with a download of an untrusted piece of code, which leads to malware infection, or pulling data from an external API, which inserts unverified data into a backend system.
Steps to mitigate the risk of supply chain attacks
The modern development lifecycle is based on CI/CD (Continuous Integration / Continuous Deployment or Delivery), we can embed security gates at various stages of the CI/CD pipeline, as explained below.
Source Code
- Scan for software vulnerabilities (such as binaries and open-source libraries), before storing components/code/libraries inside VM or container images inside an image repository.
Example of services:
- Amazon Inspector – Vulnerability scanner for Amazon EC2, container images (inside Amazon ECR), and Lambda functions
- Microsoft Defender for Containers – Vulnerability scanner for containers
- Google Container Analysis – Vulnerability scanner for containers
- Scan your code stored in your repositories, to make sure it does not contain sensitive data (such as secrets, API keys, credentials, etc.)
Example of tools:
- git-secrets
- Gitleaks
- SecretScanner
- Run static code analysis on any developed or imported code, to search for vulnerabilities.
Example of tools:
- Snyk – Scan for open-source, code, container, and Infrastructure-as-Code vulnerabilities
- Trivy – Scan for open-source, code, container, and Infrastructure-as-Code vulnerabilities
- Chekov – Scan for open-source and Infrastructure-as-Code vulnerabilities
- KICS – Scan for Infrastructure-as-Code vulnerabilities
- Terrascan – Scan for Infrastructure-as-Code vulnerabilities
- Kubescape – Scan for Kubernetes vulnerabilities
- Scan your binaries to verify their trustworthiness – especially important when you import binaries from an external source.
Example of services:
Repositories
- Create a private repository for storing source code, VM images, or container images
- Enforce authentication and authorization for who can access and make changes to the repository
- Sign all source code/images stored in the repository
- Audit access to the repositories
Example of services for storing source code:
Example of services for storing VM images:
Example of services for storing container images:
Example of service for storing serverless code:
Authentication & Authorization
- Configure authentication and authorization process (who has written permissions to the repository), and enforce the use of MFA.
Example of services:
- AWS Identity and Access Management (IAM)
- Azure Active Directory (Azure AD)
- Google Cloud Identity and Access Management (IAM)
- Store all sensitive data (such as secrets, credentials, API keys, etc.) in a secured vault, enforce key rotation, and access management to keys.
Example of services:
Handling data from external APIs
There are many cases where we rely on data from external third parties, exposed using APIs.
Since we cannot verify the trustworthiness of external data, we must follow the following guidelines:
- Never rely on unauthenticated APIs – always make sure the connectivity to the external APIs requires proper authentication (such as certificates, rotated API key, etc.) and proper
- Always make sure the remote API enforces proper authorization mechanism – if the remote API allows admin or even write access to anyone on the Internet, the data it provides is not considered trusted anymore
- Always make sure data is encrypted at transit – it allows to keep data confidentiality and provides a high degree of trust in the remote endpoint
- Always perform input validation and proper escaping, before storing data from an external source into any backend database
For further reading, see:
Summary
In the post, we have reviewed threats as a result of software supply chain vulnerabilities, and various tools and services that can assist us in securing the modern development process of cloud-native applications.
It is possible to mitigate the risks coming from the software supply chain, whether it is code that we develop in-house or code/binaries/libraries that we import from a third-party source, but we must always follow the concept of “Trust but verify”.
References
- Build your secure software supply chains on AWS
- Supply Chain Security on Amazon Elastic Kubernetes Service (Amazon EKS) using AWS Key Management Service (AWS KMS), Kyverno, and Cosign
- Best practices for a secure software supply chain
- Monitoring the Software Supply Chain with Azure Sentinel
- Software supply chain security
- Perspectives on Security – Securing Software Supply Chains
- NIST – Defending Against Software Supply Chain Attacks
- CNCF Software Supply Chain Best Practices
Automation as key to cloud adoption success
After deploying several workloads in the public cloud, making mistakes, failing, fixing, and beginning using the cloud for production workloads, it is now the time to think about the next step in cloud adoption.
To be able to fully embrace the benefits of the public cloud, the scale, the elasticity, and the short time it takes to deploy new resources, it is time to put automation in place.
Automation allows us to do the same tasks over and over again, deploying the same configuration to multiple environments (Dev, Test, Prod) and get the same results – no human errors (assuming you have tested your code…)
Automation can be achieved in various ways – from using the CLI, using the cloud vendor’s SDK (languages such as Python, Go, Java, and more), or using Infrastructure as Code (such as Terraform, AWS CloudFormation, Azure Resource Manager, and more).
In this article, we shall review some of the common alternatives for using automation using code.
Why use code?
The clear benefit of using code for automation is the ability to have change management. Simply choose your favorite source control (such as GitHub, AWS CodeCommit, Azure Repos, and more), upload your scripts and have the version history of your code, and be able to know at each stage who made changes to the code.
Another benefit of using code for automation is the fact that the Internet is full of samples you can find to automate (almost) anything in your cloud environment.
The downside of doing everything using code, is the learning curve required by your organization’s IT or DevOps teams, learning new languages, but once they pass this stage, you can have all the benefits of the scripting languages.
Automation – the AWS way
If AWS is your sole cloud provider, you should learn and start using the following built-in services or capabilities offered by AWS:
Infrastructure as Code
- AWS CloudFormation – The built-in IaC for deploying and managing AWS resources.
Reference: https://github.com/aws-cloudformation/aws-cloudformation-samples
- AWS Cloud Development Kit (AWS CDK) – Ability to write CloudFormation templates, based on common programming languages such as Python, Java, DotNet, and more.
Reference: https://github.com/aws-samples/aws-cdk-examples
Policy as Code
- Service control policies (SCPs) – Managing permissions in AWS Organizations.
Reference: https://docs.aws.amazon.com/organizations/latest/userguide/orgs_manage_policies_scps_examples.html
CI/CD pipeline
- AWS CodePipeline – A fully managed continuous delivery service.
Reference: https://docs.aws.amazon.com/codepipeline/latest/userguide/tutorials.html
Containers and Kubernetes
- Amazon ECS – Container management service based on the AWS platform.
Reference: https://docs.aws.amazon.com/AmazonECS/latest/developerguide/example_task_definitions.html
- Amazon Elastic Kubernetes Service (EKS) – Managed Kubernetes service.
Reference: https://github.com/aws-quickstart/quickstart-amazon-eks
Automation – the Azure way
If Azure is your sole cloud provider, you should learn and start using the following built-in services or capabilities offered by Azure:
Infrastructure as Code
- Azure Resource Manager templates (ARM templates) – The built-in IaC for deploying and managing Azure resources.
Reference: https://github.com/Azure/azure-quickstart-templates
- Bicep – Declarative language for deploying Azure resources.
Reference: https://github.com/Azure/azure-docs-bicep-samples
Policy as Code
- Azure Policy – Enforce organizational standards across the Azure organization.
Reference: https://github.com/Azure/azure-policy
CI/CD pipeline
- Azure Pipelines – A fully managed continuous delivery service.
Reference: https://github.com/microsoft/azure-pipelines-yaml
Containers and Kubernetes
- Azure Container Instances – Container management service based on the Azure platform.
Reference: https://docs.microsoft.com/en-us/samples/browse/?products=azure&terms=container%2Binstance
- Azure Kubernetes Service (AKS) – Managed Kubernetes service.
Reference: https://github.com/Azure/AKS
Automation – the Google Cloud way
If GCP is your sole cloud provider, you should learn and start using the following built-in services or capabilities offered by GCP:
Infrastructure as Code
- Google Cloud Deployment Manager – The built-in IaC for deploying and managing GCP resources.
Reference: https://github.com/GoogleCloudPlatform/deploymentmanager-samples
Policy as Code
- Google Organization Policy Service – Programmatic control over the organization’s cloud resources.
CI/CD pipeline
- Google Cloud Build – A fully managed continuous delivery service.
Reference: https://github.com/GoogleCloudPlatform/cloud-build-samples
Containers and Kubernetes
- Google Kubernetes Engine (GKE) – Managed Kubernetes service.
Reference: https://github.com/GoogleCloudPlatform/kubernetes-engine-samples
Automation – the cloud agnostic way
If you plan for the future, plan for multi-cloud. Look for solutions that are capable of connecting to multiple cloud environments, to decrease the learning curve of your DevOps team learning the various scripting languages and being able to deploy workloads on several cloud environments.
Infrastructure as Code
- Hashicorp Terraform – The most widely used IaC for deploying and managing resources on both cloud and on-premise.
Reference: https://registry.terraform.io/browse/providers
Policy as Code
- Hashicorp Sentinel – Policy as code framework that compliments Terraform code.
Reference: https://www.terraform.io/cloud-docs/sentinel/examples
CI/CD pipeline
- Jenkins – The most widely used open-source CI/CD tool.
Reference: https://www.jenkins.io/doc/pipeline/examples/
Containers and Kubernetes
- Docker – The most widely used container run-time for deploying applications.
Reference: https://github.com/dockersamples
- Kubernetes – The most widely used container orchestration open-source platform.
Reference: https://github.com/kubernetes/examples
Summary
In this post, I have reviewed the most common solutions that allow you to automate your workloads’ deployment, management, and maintenance using various scripting languages.
Some of the solutions are bound to a specific cloud provider, while others are considered cloud agnostic.
Use automation to fully embrace the power and benefits of the public cloud.
If you don’t have experience writing code, take the time to learn. The more you practice, the more experience you will gain.
As Werner Vogels, the Amazon CTO always says – “Go Build”.
Not all cloud providers are built the same

When organizations debate workload migration to the cloud, they begin to realize the number of public cloud alternatives that exist, both U.S hyper-scale cloud providers and several small to medium European and Asian providers.
The more we study the differences between the cloud providers (both IaaS/PaaS and SaaS providers), we begin to realize that not all cloud providers are built the same.
How can we select a mature cloud provider from all the alternatives?
Transparency
Mature cloud providers will make sure you don’t have to look around their website, to locate their security compliance documents, allow you to download their security controls documentation, such as SOC 2 Type II, CSA Star, CSA Cloud Controls Matrix (CCM), etc.
What happens if we wish to evaluate the cloud provider by ourselves?
Will the cloud provider (no matter what cloud service model), allow me to conduct a security assessment (or even a penetration test), to check the effectiveness of his security controls?
Global presence
When evaluating cloud providers, ask yourself the following questions:
- Does the cloud provider have a local presence near my customers?
- Will I be able to deploy my application in multiple countries around the world?
- In case of an outage, will I be able to continue serving my customers from a different location with minimal effort?
Scale
Deploying an application for the first time, we might not think about it, but what happens in the peak scenario?
Will the cloud provider allow me to deploy hundreds or even thousands of VM’s (or even better, containers), in a short amount of time, for a short period, from the same location?
Will the cloud provider allow me infinite scale to store my data in cloud storage, without having to guess or estimate the storage size?
Multi-tenancy
As customers, we expect our cloud providers to offer us a fully private environment.
We never want to hear about “noisy neighbor” (where one customer is using a lot of resources, which eventually affect other customers), and we never want to hear a provider admits that some or all of the resources (from VMs, database, storage, etc.) are being shared among customers.
Will the cloud provider be able to offer me a commitment to a multi-tenant environment?
Stability
One of the major reasons for migrating to the cloud is the ability to re-architect our services, whether we are still using VMs based on IaaS, databases based on PaaS, or fully managed CRM services based on SaaS.
In all scenarios, we would like to have a stable service with zero downtime.
Will the cloud provider allow me to deploy a service in a redundant architecture, that will survive data center outage or infrastructure availability issues (from authentication services, to compute, storage, or even network infrastructure) and return to business with minimal customer effect?
APIs
In the modern cloud era, everything is based on API (Application programming interface).
Will the cloud provider offer me various APIs?
From deploying an entire production environment in minutes using Infrastructure as Code, to monitoring both performances of our services, cost, and security auditing – everything should be allowed using API, otherwise, it is simply not scale/mature/automated/standard and prone to human mistakes.
Data protection
Encrypting data at transit, using TLS 1.2 is a common standard, but what about encryption at rest?
Will the cloud provider allow me to encrypt a database, object storage, or a simple NFS storage using my encryption keys, inside a secure key management service?
Will the cloud provider allow me to automatically rotate my encryption keys?
What happens if I need to store secrets (credentials, access keys, API keys, etc.)? Will the cloud provider allow me to store my secrets in a secured, managed, and audited location?
In case you are about to store extremely sensitive data (from PII, credit card details, healthcare data, or even military secrets), will the cloud provider offer me a solution for confidential computing, where I can store sensitive data, even in memory (or in use)?
Well architected
A mature cloud provider has a vast amount of expertise to share knowledge with you, about how to build an architecture that will be secure, reliable, performance efficient, cost-optimized, and continually improve the processes you have built.
Will the cloud provider offer me rich documentation on how to achieve all the above-mentioned goals, to provide your customers the best experience?
Will the cloud provider offer me an automated solution for deploying an entire application stack within minutes from a large marketplace?
Cost management
The more we broaden our use of the IaaS / PaaS service, the more we realize that almost every service has its price tag.
We might not prepare for this in advance, but once we begin to receive the monthly bill, we begin to see that we pay a lot of money, sometimes for services we don’t need, or for an expensive tier of a specific service.
Unlike on-premise, most cloud providers offer us a way to lower the monthly bill or pay for what we consume.
Regarding cost management, ask yourself the following questions:
Will the cloud provider charge me for services when I am not consuming them?
Will the cloud provider offer me detailed reports that will allow me to find out what am I paying for?
Will the cloud provider offer me documents and best practices for saving costs?
Summary
Answering the above questions with your preferred cloud provider, will allow you to differentiate a mature cloud provider, from the rest of the alternatives, and to assure you that you have made the right choice selecting a cloud provider.
The answers will provide you with confidence, both when working with a single cloud provider, and when taking a step forward and working in a multi-cloud environment.
References
Security, Trust, Assurance, and Risk (STAR)
https://cloudsecurityalliance.org/star/
SOC 2 – SOC for Service Organizations: Trust Services Criteria
https://www.aicpa.org/interestareas/frc/assuranceadvisoryservices/aicpasoc2report.html
Confidential Computing and the Public Cloud
https://eyal-estrin.medium.com/confidential-computing-and-the-public-cloud-fa4de863df3
Confidential computing: an AWS perspective
https://aws.amazon.com/blogs/security/confidential-computing-an-aws-perspective/
AWS Well-Architected
https://aws.amazon.com/architecture/well-architected
Azure Well-Architected Framework
https://docs.microsoft.com/en-us/azure/architecture/framework/
Google Cloud’s Architecture Framework
https://cloud.google.com/architecture/framework
Oracle Architecture Center
https://docs.oracle.com/solutions/
Alibaba Cloud’s Well-Architectured Framework
Tips for Selecting a Public Cloud Provider

When an organization needs to select a public cloud service provider, there are several variables and factors to take into consideration that will help you choose the most appropriate cloud provider suitable for the organization’s needs.
In this post, we will review various considerations that will help organizations in the decision-making process.
Business goals
Before deciding to use a public cloud solution, or migrating existing environments to the cloud, it is important that organizations review their business goals. Explore what brings the organization value by maintaining existing systems on premise and what value does the migration to the cloud promise. In accordance with what you discover, decide which systems will be deployed in the cloud first, or which systems your organization will choose to use as managed services.
Review the lists of services offered in the cloud
Public cloud providers publish a list of services in various areas.
Review the list of current services and see how they stand up to your organization’s needs. This will help you narrow down the most suitable options.
Here are some examples of public cloud service catalogs:
· AWS — https://aws.amazon.com/products/
· Azure — https://azure.microsoft.com/en-us/services/
· GCP — https://cloud.google.com/products
· Oracle Cloud — https://www.oracle.com/cloud/products.html
· IBM — https://www.ibm.com/cloud/products
· Salesforce — https://www.salesforce.com/eu/products/
· SAP — https://www.sap.com/products.html
Centrally authenticating users against Active Directory in IaaS / PaaS environments
Many organizations manage access rights to various systems based on an organizational Active Directory.
Although it is possible to deploy Domain Controllers based on virtual servers in an IaaS environment, or create a federation between the on-premise and the cloud environments, at least some cloud providers offer managed Active Directory service based on Kerberos protocol (the most common authentication protocol in the on-premise environments) might ease the migration to the public cloud.
Examples of managed Active Directory services:
· Azure Active Directory Domain Services
· Google Managed Service for Microsoft Active Directory
Understanding IaaS / PaaS pricing models
Public cloud providers publish pricing calculators and documentation on their service pricing models.
Understanding pricing models might be complex for some services. For this reason, it is highly recommended to contact an account manager, a partners or reseller for assistance.
Comparing similar services among different cloud providers will enable an organization to identify and choose the most suitable cloud provider based on the organization’s needs and budget.
Examples of pricing calculators:
· AWS Simple Monthly Calculator
· Google Cloud Platform Pricing Calculator
Check if your country has a local region of one of the public cloud providers
The decision may be easier, or it may be easier to select one provider over a competitor, if in your specific country the provider has a local region. This can help for example in cases where there are limitations on data transfer outside a specific country’s borders (or between continents), or issues of network latency when transferring large amount of data sets between the local data centers and cloud environments,
This is relevant for all cloud service models (IaaS / PaaS / SaaS).
Examples of regional mapping:
· AWS:
AWS Regions and Availability Zones
· Azure and Office 365:
o Where your Microsoft 365 customer data is stored
· Google Cloud Platform:
· Oracle Cloud:
Oracle Data Regions for Platform and Infrastructure Services
· Salesforce:
Where is my Salesforce instance located?
· SAP:
SAP Cloud Platform Regions and Service Portfolio
Service status reporting and outage history
Mature cloud providers transparently publish their service availability status in various regions around the world, including outage history of their services.
Mature cloud providers transparently share service status and outages with customers, and know how to build stable and available infrastructure over the long term, and over multiple geographic locations, as well as how to minimize the “blast radius”, which might affect many customers.
A thorough review of an outage history report allows organizations to get a good picture over an extended period and help in the decision-making process.
Example of cloud providers’ service status and outage history documentation:
· AWS:
· Azure:
· Google Cloud Platform:
Google Cloud Status Dashboard — Incidents Summary
· Oracle Cloud:
Oracle Cloud Infrastructure — Current Status
Oracle Cloud Infrastructure — Incident History
· Salesforce:
· SAP:
SAP Cloud Platform Status Page
Summary
As you can see, there are several important factors to take into consideration when selecting a specific cloud provider. We have covered some of the more common ones in this post.
For an organization to make an educated decision, it is recommended to check what brings value for the organization, in both the short and long-term. It is important to review cloud providers’ service catalogs, alongside a thorough review of global service availability, transparency, understanding pricing models and hybrid architecture that connects local data centers to the cloud.
Benefits of using managed database as a service in the cloud

When using public cloud services for relational databases, you have two options:
- IaaS solution – Install a database server on top of a virtual machine
- PaaS solution – Connect to a managed database service
In the traditional data center, organizations had to maintain the operating system and the database by themselves.
The benefits are very clear – full control over the entire stack.
The downside – The organization needs to maintain availability, license cost and security (access control, patch level, hardening, auditing, etc.)
Today, all the major public cloud vendors offer managed services for databases in the cloud.
To connect to the database and begin working, all a customer needs is a DNS name, port number and credentials.
The benefits of a managed database service are:
- Easy administration – No need to maintain the operating system (including patch level for the OS and for the database, system hardening, backup, etc.)
- Scalability – The number of virtual machines in the cluster will grow automatically according to load, in addition to the storage space required for the data
- High availability – The cluster can be configured to span across multiple availability zones (physical data centers)
- Performance – Usually the cloud provider installs the database on SSD storage
- Security – Encryption at rest and in transit
- Monitoring – Built-in the service
- Cost – Pay only for what you use
Not all features available on the on-premises version of the database are available on the PaaS version, and not all common databases are available as managed service of the major cloud providers.
Amazon RDS
Amazon managed services currently (as of April 2018) supports the following database engines:
- Microsoft SQL Server (2008 R2, 2012, 2014, 2016, and 2017)
Amazon RDS for SQL Server FAQs:
https://aws.amazon.com/rds/sqlserver/faqs
Known limitations:
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_SQLServer.html#SQLServer.Concepts.General.FeatureSupport.Limits
- MySQL (5.5, 5.6 and 5.7)
Amazon RDS for MySQL FAQs:
https://aws.amazon.com/rds/mysql/faqs
Known limitations:
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/MySQL.KnownIssuesAndLimitations.html
- Oracle (11.2 and 12c)
Amazon RDS for Oracle Database FAQs:
https://aws.amazon.com/rds/oracle/faqs
Known limitations:
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_Limits.html
- PostgreSQL (9.3, 9.4, 9.5, and 9.6)
Amazon RDS for PostgreSQL FAQs:
https://aws.amazon.com/rds/postgresql/faqs
Known limitations:
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_PostgreSQL.html#PostgreSQL.Concepts.General.Limits
- MariaDB (10.2)
Amazon RDS for MariaDB FAQs:
https://aws.amazon.com/rds/mariadb/faqs
Known limitations:
https://docs.aws.amazon.com/AmazonRDS/latest/UserGuide/CHAP_Limits.html
Azure Managed databases
Microsoft Azure managed database services currently (as of April 2018) support the following database engines:
- Azure SQL Database
Technical overview:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-technical-overview
Known limitations:
https://docs.microsoft.com/en-us/azure/sql-database/sql-database-dtu-resource-limits
- MySQL (5.6 and 5.7)
Technical overview:
https://docs.microsoft.com/en-us/azure/mysql/overview
Known limitations:
https://docs.microsoft.com/en-us/azure/mysql/concepts-limits
- PostgreSQL (9.5, and 9.6)
Technical overview:
https://docs.microsoft.com/en-us/azure/postgresql/overview
Known limitations:
https://docs.microsoft.com/en-us/azure/postgresql/concepts-limits
Google Cloud SQL
Google managed database services currently (as of April 2018) support the following database engines:
- MySQL (5.6 and 5.7)
Product documentation:
https://cloud.google.com/sql/docs/mysql
Known limitations:
https://cloud.google.com/sql/docs/mysql/known-issues
- PostgreSQL (9.6)
Product documentation:
https://cloud.google.com/sql/docs/postgres
Known limitations:
https://cloud.google.com/sql/docs/postgres/known-issues
Oracle Database Cloud Service
Oracle managed database services currently (as of April 2018) support the following database engines:
- Oracle (11g and 12c)
Product documentation:
https://cloud.oracle.com/en_US/database/features
Known issues:
https://docs.oracle.com/en/cloud/paas/database-dbaas-cloud/kidbr/index.html#KIDBR109
- MySQL (5.7)
Product documentation:
https://cloud.oracle.com/en_US/mysql/features
Cloud Providers Service Limits

When working with cloud service providers, you may notice that at some point there are service / quota limitations.
Some limits are per account / subscription; some of them are per region and some limits are per pricing tier (free tier vs billable).
Here are some of the most common reasons for service / quota limitations:
- Performance issues on the cloud provider’s side – loading a lot of virtual machines on the same data center requires a lot of resources from the cloud provider
- Avoiding spikes in usage – protect from a situation where one customer consumes a lot of resources that might affect other customers and might eventually cause denial of service
For more information about default cloud service limits, see:
- AWS Service Limits:
https://docs.aws.amazon.com/general/latest/gr/aws_service_limits.html - Azure subscription and service limits, quotas, and constraints:
https://docs.microsoft.com/en-us/azure/azure-subscription-service-limits - Google App Engine Quotas:
https://cloud.google.com/appengine/quotas - Oracle Cloud Service Limits:
https://docs.us-phoenix-1.oraclecloud.com/Content/General/Concepts/servicelimits.htm
Default limitations can be changed by contacting the cloud service provider’s support and requesting a change to the default limitation.
For instructions on how to change the service limitations, see:
- How do I manage my AWS service limits?
https://aws.amazon.com/premiumsupport/knowledge-center/manage-service-limits/ - Understanding Azure Limits and Increases
https://azure.microsoft.com/en-us/blog/azure-limits-quotas-increase-requests/ - Google Resource Quotas
https://cloud.google.com/compute/quotas#request_quotas - Oracle Cloud – Requesting a Service Limit Increase
https://docs.us-phoenix-1.oraclecloud.com/Content/General/Concepts/servicelimits.htm#three