How to Avoid Cloud Repatriation

I have been working with public clouds since 2015, and in the past couple of months I see more and more discussions (on newsletters, LinkedIn, and technical forums) about a term called “Cloud Repatriation”.
In this post, I will share my opinion on “Cloud Repatriation” and how I believe organizations can better prepare themselves in advance, to avoid such scenarios.
What is Cloud Repatriation?
Cloud repatriation is when a company decides to move existing workloads from the public cloud to its data centers or co-location facilities.
The main reason companies decide on such a drastic move (after already investing in the public cloud) is due to cost.
About a decade ago, when companies considered moving to the public cloud, there was a myth that moving to the cloud will allow companies to save money on IT spending.
Another myth about the public cloud that caused companies to re-think about the move to the cloud was the ability to easily migrate existing workloads from the on-premise to the cloud using a “lift & shift” strategy (also known as “we will re-architect it later…”), which in the long term found out to be perhaps the worst strategy to move applications to the cloud.
I am not suggesting that the public cloud is suitable to run 100% of the workloads currently running on-premise – there are scenarios where your company would leave workloads locally due to legacy application constraints, latency issues (if there is no public cloud region in your country), or regulatory constraints.
So how do we prepare our company in advance, to avoid decisions such as going back on-premise?
Cloud Strategy
The ideal time to create a cloud strategy is before deploying the first workload in the public cloud.
Even if your company already deployed a playground for gaining experience with the cloud, it still has time to invest in a cloud strategy.
The most important thing to keep in mind is that the public cloud allows us many capabilities, with a single goal – serving our business and providing us with business value.
The goal is never to migrate to the cloud just for the sake of migration.
We always need to ask ourselves – how can we use the public cloud to enable our business?
Another important question we need to ask ourselves – what systems/applications do we currently have and which of them are we going to move to the cloud or are worth the effort to move to the cloud?
Even if our cloud strategy to going “cloud first”, it does not mean 100% of our applications will be migrated to the cloud – it only means that we will review each existing or new application if they are suitable to run in the cloud, and our priority is to move applications to the cloud (when feasible and when it makes sense in terms of cost, effort and technology capabilities).
Important note – having a cloud strategy is not enough – we must review and update our strategy regularly, according to our business requirements.
Architectural Decisions
To gain the most value from the public cloud, we need to consider the most suitable way to run our applications in the cloud.
Although virtualization is still a valid option, it might not be the best option.
Moving to the public cloud is a perfect time to consider modern deployments.
Containerization is very popular both in the public cloud and in companies developing cloud-native applications.
The cloud offers us an easy way to run containers based on managed Kubernetes services, allowing us to focus on our business requirements, while leaving the maintenance of the control plan to the cloud provider.
Another option the gain benefit from the cloud is to use serverless – although each cloud provider has its alternative for running serverless (or Function as a Service), it does provide us with an easy way to run cloud-native applications, while taking benefit of the entire cloud providers eco-system.
Having a regular review of our workload architecture will allow us to make changes and take the full benefit of the public cloud – from scale, elasticity, and rich service eco-system.
Financial Management
I mentioned earlier that one of the reasons companies consider the public cloud to be more expansive than managing their data centers is because they tend to compare slightly different things.
Running our data centers requires us to take care of physical security, power, cooling, and redundancy for everything we use.
In the public cloud, the cloud provider takes responsibility for managing the data centers, including the manpower required to run their data center, and the cost of using compute, network, storage, and software license – everything is embedded as part of the price we pay for consuming resources in the cloud.
Migrating workloads to the cloud, without understanding the importance of cost or financial management aspects will lead to disappointment from the cloud or to high monthly or yearly costs.
We must understand our cloud provider(s) pricing options (from on-demand, reserved instances / saving plans, to spot instances).
We need to match the most suitable pricing option to our target service or workload, and we need to have trained employees (such as DevOps, engineers, developers, or architects) monitoring, reviewing, and regularly adjusting the pricing options to our workloads.
Failing to monitor the service cost, will end up with a high bill.
Employee Training / Awareness
This is the most important thing to invest in.
Migrating to the cloud requires investment in training our employees.
Our employees need to have a solid understanding of how services run on the cloud, what is the most suitable service to select for each workload, when to choose virtualization, and when to use modern compute services such as containers or serverless.
If we are considering multi-cloud, we need to make sure our employees are trained and knowledgeable in running various workloads and multiple services on top of multiple different cloud providers (a well-known challenge for any company).
We need to invest in training our employees about automation – from provisioning the entire environment using Infrastructure-as-Code to writing automation scripts to take actions (such as powering down idle VMs, performing data replication, and more).
Summary
Moving to the cloud might be challenging for small, medium, or legacy organizations.
Running to the cloud without preparations will be both a costly and disappointing decision.
If we prepare in advance, develop a cloud strategy, and invest in employee training, we will be able to get the most value out of the public cloud and minimize the chance for cloud repatriation.
Additional References
- Importance of cloud strategy
https://eyal-estrin.medium.com/importance-of-cloud-strategy-cf37ee31bec9
- Introduction to cloud financial management on AWS
https://eyal-estrin.medium.com/introduction-to-cloud-financial-management-on-aws-cc23e564c365
- What is cloud repatriation?
Comparing Confidential Computing Alternatives in the Cloud
In 2020, I have published the blog post “Confidential Computing and the Public Cloud“.
Now, let us return to the subject of confidential computing and see what has changed among cloud providers.
Before we begin our conversation, let us define what is “Confidential Computing”, according to The Confidential Computing Consortium:
“Confidential Computing is the protection of data in use by performing the computation in a hardware-based, attested Trusted Execution Environment“
Source: https://confidentialcomputing.io/about
Introduction
When we store data in the cloud, there are various use cases where we would like to protect data from unauthorized access (from an external attacker to an internal employee and up to a cloud provider engineer who potentially might have access to customers’ data).
To name a few examples of data who would like to protect – financial data (such as credit card information), healthcare data (PHI – Personal Health Information), private data about a persona (PII – Personally Identifiable Information), government data, military data, and more.
When we would like to protect data in the cloud, we usually encrypt it in transit (with protocols such as TLS) and at rest (with algorithms such as AES).
At some point in time, either an end-user or a service needs access to the encryption keys and the data is decrypted in the memory of the running machine.
Confidential computing comes to solve the problem, by encrypting data while in use, and this is done using a hardware-based Trusted Execution Environment (TEE), also known as the hardware root of trust.
The idea behind it is to decrease the reliance on proprietary software and provide security at the hardware level.
To validate that data is protected and has not been tampered with, confidential computing performs a cryptographic process called attestation, which allows the customer to audit and make sure data was not tempered by any unauthorized party.
There are two approaches to achieving confidential computing using hardware-based TEEs:
- Application SDKs – The developer is responsible for data partitioning and encryption. Might be influenced by programming language and specific hardware TEEs.
- Runtime deployment systems – Allows the development of cross-TEE portable applications.
As of March 2023, the following are the commonly supported hardware alternatives to achieve confidential computing or encryption in use:
- Intel Software Guard Extensions (Intel SGX)
- AMD Secure Encrypted Virtualization (SEV), based on AMD EPYC processors
AWS took a different approach when they released the AWS Nitro Enclaves technology.
The AWS Nitro System is made from Nitro Cards (to provision and manage compute, memory, and storage), Nitro Security Chip (the link between the CPU and the place where customer workloads run), and the Nitro Hypervisor (receive virtual machine management commands and assign functions to the Nitro hardware interfaces).
Cloud Providers Comparison
All major cloud providers have their implementation and services that support confidential computing.
Below are the most used services supporting confidential computing:
Virtual Machine supported instance types
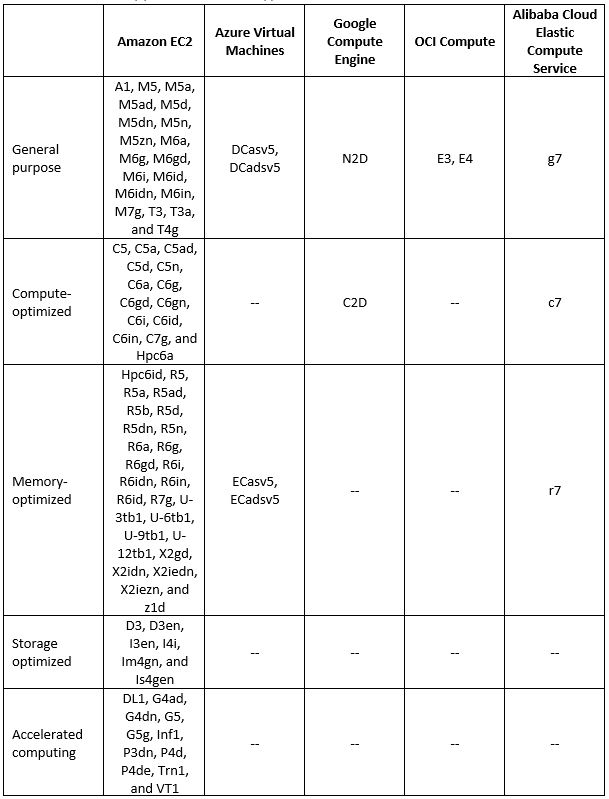
Additional References:
- Instances built on the AWS Nitro System
- Azure Confidential VMs
- Introducing high-performance Confidential Computing with N2D and C2D VMs
- Oracle Cloud Infrastructure Confidential Computing
- Alibaba Cloud – Build a confidential computing environment by using Enclave
Managed Relational Database supported instance types

Additional References:
Managed Containers Services Comparison
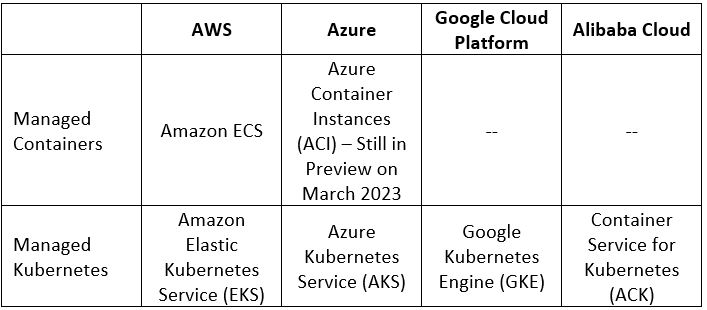
Additional References:
- Using Enclaves with Amazon EKS
- Azure Confidential containers
- Encrypt workload data in use with Confidential Google Kubernetes Engine Nodes
- Alibaba Cloud Container Service for Kubernetes (ACK) clusters supports confidential computing
Managed Hadoop Services supported instance types
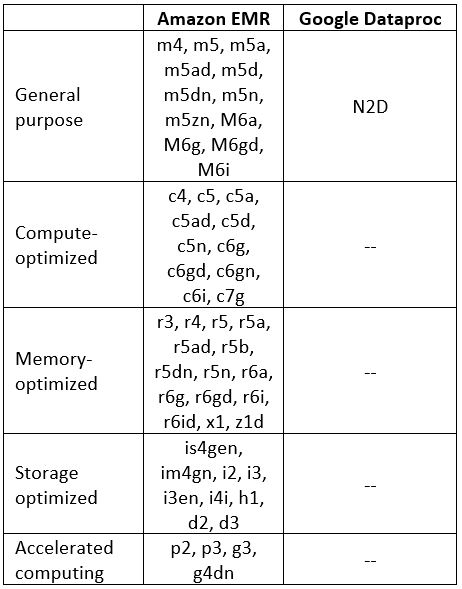
Additional References:
Summary
In this blog post, we have learned what confidential computing means, how it works, and why would we as customers need confidential computing to keep the privacy of our data stored in the public cloud.
We have also compared major cloud providers offering confidential computing-supported services.
The field of confidential computing continues to evolve – both from cloud providers adding more services to support confidential computing and allowing customers to have confidence storing data in the cloud and from third-party security vendors, offering cross-cloud platforms solutions, allowing an easy way to secure data in the cloud.
I encourage everyone to read and expand their knowledge about confidential computing implementations.
Additional References:
Introduction to Cloud Load-Balancers

We have been using load-balancing technology for many years.
What is the purpose of load-balancers and what are the alternatives offered as managed services by the public cloud providers?
Terminology
Below are some important concepts regarding cloud load-balancers:
- Private / Internal Load-Balancer – A load-balancer serving internal traffic (such as traffic from public websites to a back-end database)
- Public / External Load-Balancer – A load-balancer that exposes a public IP and serves external traffic (such as traffic from customers on the public Internet to an external website)
- Regional Load-Balancer – A load-balancer that is limited to a specific region of the cloud provider
- Global Load-Balancer – A load-balancer serving customers from multiple regions around the world using a single public IP
- TLS Termination / Offloading – A process where a load-balancer decrypt encrypted incoming traffic, for further analysis (such as traffic inspection) and either pass the traffic to the back-end nodes decrypted (offloading the encrypted traffic) or pass the traffic encrypted to the back-end nodes
What are the benefits of using load balancers?
Load-balancers offer our applications the following benefits:
- Increased scalability – combined with “auto-scale” we can benefit from the built-in elasticity of cloud services, allowing us to increase or decrease the amount of compute services (such as VMs, containers, and database instances) according to our application’s load
- Redundancy – load-balancers allow us to send traffic to multiple back-end servers (or containers), and in case of a failure in a specific back-end node, the load-balancer will send traffic to other healthy nodes, allowing our service to continue serving customers
- Reduce downtime – consider a scenario where we need to schedule maintenance work (such as software upgrades in a stateful architecture), using a load-balancer, we can remove a single back-end server (or container), drain the incoming traffic, and send new customers’ requests to other back-end nodes, without affecting the service
- Increase performance – assuming our service suffers from a peak in traffic, adding more back-end nodes will allow us a better performance to serve our customers
- Manage failures – one of the key features of a load-balancer is the ability to check the health status of the back-end nodes, and in case one of the nodes does not respond (or function as expected), the load-balancer will not send new traffic to the failed node
Layer 4 Load-Balancers
The most common load-balancers operate at layer 4 of the OSI model (the network/transport layer), and usually, we refer to them as network load-balancers.
The main benefit of a network load balancer is extreme network performance.
Let us compare the cloud providers’ alternatives:
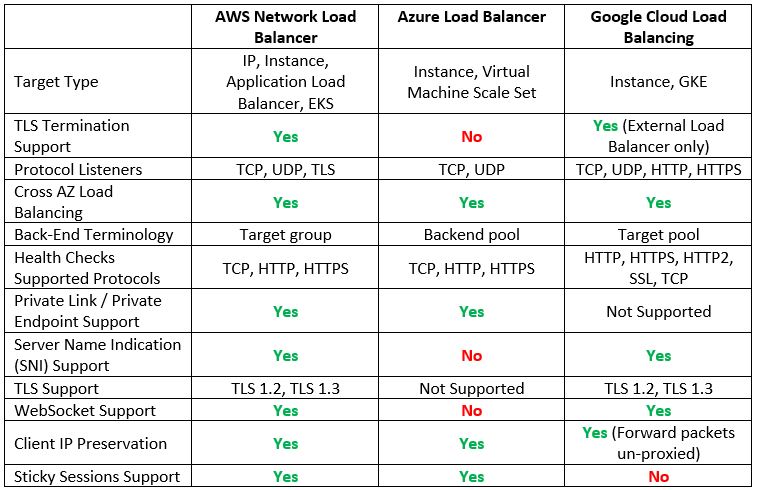
Additional reference
- What is a Network Load Balancer?
https://docs.aws.amazon.com/elasticloadbalancing/latest/network/introduction.html
- What is Azure Load Balancer?
https://learn.microsoft.com/en-us/azure/load-balancer/load-balancer-overview
- Google Cloud Load Balancing overview
https://cloud.google.com/load-balancing/docs/load-balancing-overview
Layer 7 Load-Balancers
When we need to load balance modern applications traffic, we use application load balancers, which operate at layer 7 of the OSI model (the application layer).
Layer 7 load-balancers have an application awareness, meaning you can configure routing rules to route traffic to two different versions of the same application (using the same DNS name), but with different URLs.
Let us compare the cloud providers’ alternatives:
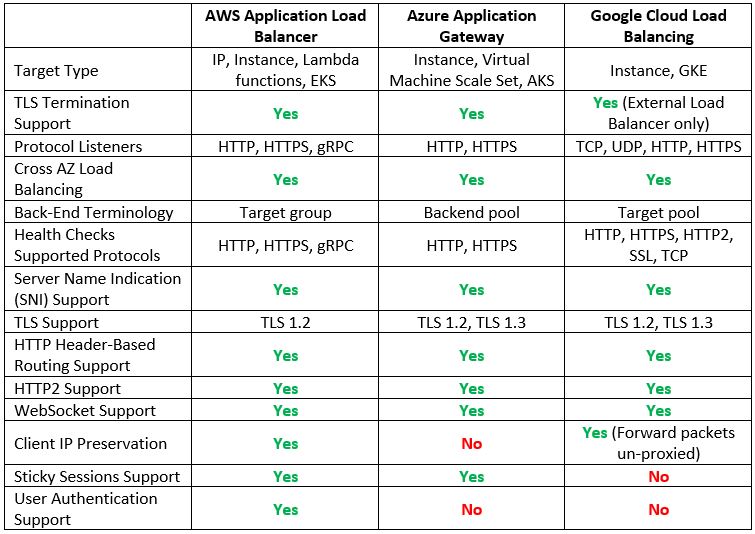
Additional reference
- What is an Application Load Balancer?
https://docs.aws.amazon.com/elasticloadbalancing/latest/application/introduction.html
- What is Azure Application Gateway?
https://learn.microsoft.com/en-us/azure/application-gateway/overview
Global Load-Balancers
Although only Google has a native global load balancer, both AWS and Azure have alternatives, which allow us to configure a multi-region architecture serving customers from multiple regions around the world.
Let us compare the cloud providers’ alternatives:
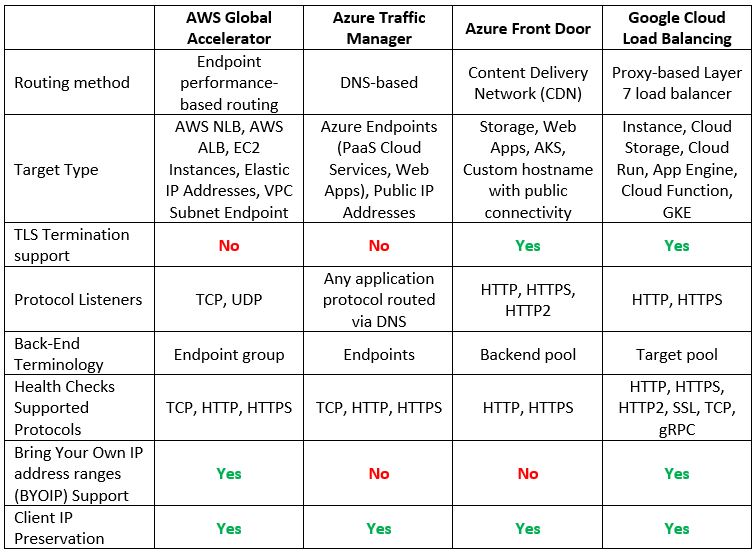
Additional reference
- What is AWS Global Accelerator?
https://docs.aws.amazon.com/global-accelerator/latest/dg/what-is-global-accelerator.html
- What is Traffic Manager?
https://learn.microsoft.com/en-us/azure/traffic-manager/traffic-manager-overview
- What is Azure Front Door?
https://learn.microsoft.com/en-us/azure/frontdoor/front-door-overview
Summary
In this blog post, we have reviewed why we need cloud load balancers when designing scalable and highly available architectures.
We reviewed the different types of managed cloud load balancers and compared the hyper-scale public cloud providers and their various capabilities.
When designing a modern application, considering network aspects (such as internal, external, or even global availability requirements), will allow you better application performance, availability, and customer experience.
Additional references
- AWS Elastic Load Balancing features
https://aws.amazon.com/elasticloadbalancing/features
- Azure Load-balancing options
- Google Cloud Load balancer feature comparison
Designing Production Workloads in the Cloud

Whether we serve internal customers or external customers over the public Internet, we all manage production workloads at some stage in the application lifecycle.
In this blog post, I will review various aspects and recommendations when managing production workloads in the public cloud (although, some of them may be relevant for on-premise as well).
Tip #1 – Think big, plan for large scale
Production workloads are meant to serve many customers simultaneously.
Don’t think about the first 1000 customers who will use your application, plan for millions of concurrent connections from day one.
Take advantage of the cloud elasticity when you plan your application deployment, and use auto-scaling capabilities to build a farm of virtual machines or containers, to be able to automatically scale in or scale out according to application load.
Using event-driven architecture will allow you a better way to handle bottlenecks on specific components of your application (such as high load on front web servers, API gateways, backend data store, etc.)
Tip #2 – Everything breaks, plan for high availability
No business can accept downtime of a production application.
Always plan for the high availability of all components in your architecture.
The cloud makes it easy to design highly-available architectures.
Cloud infrastructure is built from separate geographic regions, and each region has multiple availability zones (which usually means several distinct data centers).
When designing for high availability, deploy services across multiple availability zones, to mitigate the risk of a single AZ going down (together with your production application).
Use auto-scaling services such as AWS Auto Scaling, Azure Autoscale, or Google Autoscale groups.
Tip #3 – Automate everything
The days we used to manually deploy servers and later manually configure each server are over a long time ago.
Embrace the CI/CD process, and build steps to test and provision your workloads, from the infrastructure layer to the application and configuration layer.
Take advantage of Infrastructure-as-Code to deploy your workloads.
Whether you are using a single cloud vendor and putting efforts into learning specific IaC language (such as AWS CloudFormation, Azure Resource Manager, or Google Cloud Deployment Manager), or whether you prefer to learn and use cloud-agnostic IaC language such as Terraform, always think about automation.
Automation will allow you to deploy an entire workload in a matter of minutes, for DR purposes or for provisioning new versions of your application.
Tip #4 – Limit access to production environments
Traditional organizations are still making the mistake of allowing developers access to production, “to fix problems in production”.
As a best practice human access to production workloads must be prohibited.
For provisioning of new services or making changes to existing services in production, we should use CI/CD process, running by a service account, in a non-interactive mode, following the principle of least privilege.
For troubleshooting or emergency purpose, we should create a break-glass process, allowing a dedicated group of DevOps or Service Reliability Engineers (SREs) access to production environments.
All-access attempts must be audited and kept in an audit system (such as SIEM), with read permissions for the SOC team.
Always use secure methods to login to operating systems or containers (such as AWS Systems Manager Session Manager, Azure Bastion, or Google Identity-Aware Proxy)
Enforce the use of multi-factor authentication (MFA) for all human access to production environments.
Tip #5 – Secrets Management
Static credentials of any kind (secrets, passwords, certificates, API keys, SSH keys) are prone to be breached when used over time.
As a best practice, we must avoid storing static credentials or hard-code them in our code, scripts, or configuration files.
All static credentials must be generated, stored, retrieved, rotated, and revoked automatically using a secrets management service.
Access to the secrets management requires proper authentication and authorization process and is naturally audited and logs must be sent to a central logging system.
Use Secrets Management services such as AWS Secrets Manager, Azure Key Vault, or Google Secret Manager.
Tip #6 – Auto-remediation of vulnerabilities
Vulnerabilities can arise for various reasons – from misconfigurations to packages with well-known vulnerabilities to malware.
We need to take advantage of cloud services and configure automation to handle the following:
- Vulnerability management – Run vulnerability scanners on regular basis to automatically detect misconfigurations or deviations from configuration standards (services such as Amazon Inspector, Microsoft Defender, or Google Security Command Center).
- Patch management – Create automated processes to check for missing OS patches and use CI/CD processes to push security patches (services such as AWS Systems Manager Patch Manager, Azure Automation Update Management, or Google OS patch management).
- Software composition analysis (SCA) – Run SCA tools as part of the CI/CD process to automatically detect open-source libraries/packages with well-known vulnerabilities (services such as Amazon Inspector for ECR, Microsoft Defender for Containers, or Google Container Analysis).
- Malware – If your workload contains virtual machines, deploy anti-malware software at the operating system level, to detect and automatically block malware.
- Secure code analysis – Run SAST / DAST tools as part of the CI/CD process, to detect vulnerabilities in your code (if you cannot auto-remediate, at least break the build process).
Tip #7 – Monitoring and observability
Everything will eventually fail.
Log everything – from system health, performance logs, and application logs to user experience logs.
Monitor the entire service activity (from the operating system, network, application, and every part of your workload).
Use automated services to detect outages or service degradation and alert you in advance, before your customers complain.
Use services such as Amazon CloudWatch, Azure Monitor, or Google Cloud Logging.
Tip #8 – Minimize deviations between Dev, Test, and Production environments
Many organizations still believe in the false sense that lower environments (Dev, Test, QA, UAT) can be different from production, and “we will make all necessary changes before moving to production”.
If you build your environments differently, you will never be able to test changes or new versions of your applications/workloads in a satisfying manner.
Use the same hardware (from instance type, amount of memory, CPU, and storage type) when provisioning compute services.
Provision resources to multiple AZs, in the same way, as provision for production workloads.
Use the same Infrastructure-as-Code to provision all environments, with minor changes such as tagging indicating dev/test/prod, different CIDRs, and different endpoints (such as object storage, databases, API gateway, etc.)
Some managed services (such as API gateways, WAF, DDoS protection, and more), has different pricing tiers (from free, standard to premium), allowing you to consume different capabilities or features – conduct a cost-benefit analysis and consider the risk of having different pricing tiers for Dev/Test vs. Production environments.
Summary
Designing production workloads have many aspects to consider.
We must remember that production applications are our face to our customers, and as such, we would like to offer highly-available and secured production applications.
This blog post contains only part of the knowledge required to design, deploy, and operate production workloads.
I highly recommend taking the time to read vendor documentation, specifically the well-architected framework documents – they contain information gathered by architects, using experience gathered over years from many customers around the world.
Additional references
- AWS Well-Architected Framework
https://docs.aws.amazon.com/wellarchitected/latest/framework/welcome.html
- Microsoft Azure Well-Architected Framework
https://learn.microsoft.com/en-us/azure/architecture/framework
- Google Cloud Architecture Framework
Is the Public Cloud Ready for IPv6?
When connecting machines over the public Internet (or over private networks), we use IPv4 addresses.
For many years we heard about IPv4 address exhaustion or the fact that sometime in the future we will not able to request new IPv4 addresses to connect over the public Internet.
We all heard that IPv6 address space will resolve our problem, but is it?
In this blog post, I will try to compare common use cases for using cloud services and see if they are ready for IPv6.
Before we begin, when working with IPv6, we need to clarify what “Dual Stack” means – A device with dual-stack implementation in the operating system has an IPv4 and IPv6 address, and can communicate with other nodes in the LAN or the Internet using either IPv4 or IPv6.
Source: https://en.wikipedia.org/wiki/IPv6
Step 1 – Cloud Network Infrastructure
The first step in building our cloud environment begins with the network services.
The goal is to be able to create a network environment with subnets, an access control list, be able to create peering between cloud accounts (for the same cloud provider), and get ingress access to our cloud environment (either from the public Internet or from our on-premise data center).
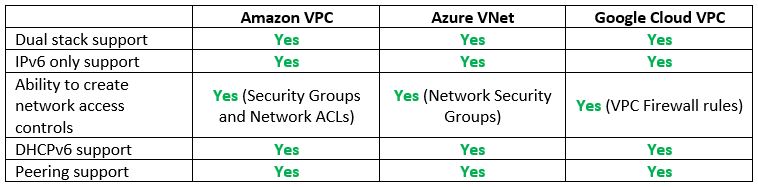
Vendor documentation:
- AWS VPC that supports IPv6 addressing
https://docs.aws.amazon.com/vpc/latest/userguide/get-started-ipv6.html
- What is IPv6 for Azure Virtual Network?
https://learn.microsoft.com/en-us/azure/virtual-network/ip-services/ipv6-overview
- Google VPC networks
https://cloud.google.com/vpc/docs/vpc
Step 2 – Private Network Connectivity – Managed VPN Services
Now that we have a network environment in the cloud, how do we connect to it from our on-premise data center using Site-to-Site VPN?
Let us compare the cloud providers’ alternatives:

Vendor documentation:
- Hybrid connectivity design – Amazon-managed VPN
- Google Cloud VPN overview – IPv6 support
https://cloud.google.com/network-connectivity/docs/vpn/concepts/overview#ipv6_support
Step 3 – Private Network Connectivity – Dedicated Network Connections
Assuming we managed to create a VPN tunnel between our on-premise data center and the cloud environment, what happens if we wish to set up a dedicated network connection (and have low latency and promised bandwidth)?
Let us compare the cloud providers’ alternatives:
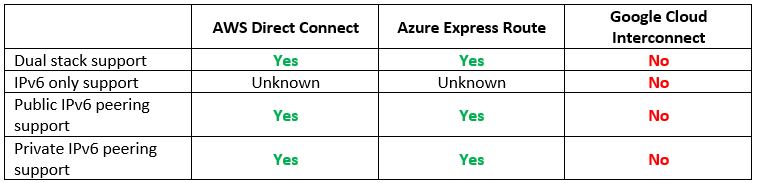
Vendor documentation:
- Hybrid connectivity design – AWS Direct Connect
- Add IPv6 support for private peering using the Azure portal
https://learn.microsoft.com/en-us/azure/expressroute/expressroute-howto-add-ipv6-portal
- Create and manage ExpressRoute public peering
https://learn.microsoft.com/en-us/azure/expressroute/about-public-peering
- Can I reach my instances using IPv6 over Cloud Interconnect?
https://cloud.google.com/network-connectivity/docs/interconnect/support/faq#ipv6
Step 4 – Private Network Connectivity – Resources on the subnet level
We have managed to provision the network environment in the cloud using IPv6.
What happens if we wish to connect to managed services using private network connectivity (inside the cloud provider’s backbone and not over the public Internet)?
Let us compare the cloud providers’ alternatives:

Vendor documentation:
- Expedite your IPv6 adoption with PrivateLink services and endpoints
- Create a Private Link service by using the Azure portal
Step 5 – Name Resolution – Managed DNS Service
In the previous step we configured network infrastructure, now, before provisioning resources, let us make sure we can access resources, meaning having a managed DNS service.
By name resolution, I mean both external customers over the public Internet and name resolution from our on-premise data centers.
Let us compare the cloud providers’ alternatives:

Vendor documentation:
- Designing DNS for IPv6
https://docs.aws.amazon.com/whitepapers/latest/ipv6-on-aws/designing-dns-for-ipv6.html
- Azure DNS FAQ
https://learn.microsoft.com/en-us/azure/dns/dns-faq
- General Google Cloud DNS overview
https://cloud.google.com/dns/docs/dns-overview
Step 6 – Resource Provisioning – Compute (Virtual Machines)
In the previous steps we have set up the network infrastructure and name resolution, and now it is time to provision resources.
The most common resource we can find in IaaS is compute or virtual machines.
Let us compare the cloud providers’ alternatives:

Vendor documentation:
- Amazon EC2 IPv6 addresses
https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-instance-addressing.html#ipv6-addressing
- Create an Azure Virtual Machine with a dual-stack network using the Azure portal
https://learn.microsoft.com/en-us/azure/virtual-network/ip-services/create-vm-dual-stack-ipv6-portal
- Configuring IPv6 for instances and instance templates
https://cloud.google.com/compute/docs/ip-addresses/configure-ipv6-address
Step 7 – Resource Provisioning – Compute (Managed Kubernetes)
Another common use case is to provision containers based on a managed Kubernetes service.
Let us compare the cloud providers’ alternatives:

Vendor documentation:
- Running IPv6 EKS Clusters
https://aws.github.io/aws-eks-best-practices/networking/ipv6/
- Use dual-stack kubenet networking in Azure Kubernetes Service (AKS) (Preview)
https://learn.microsoft.com/en-us/azure/aks/configure-kubenet-dual-stack?tabs=azure-cli%2Ckubectl
- GKE – IPv4/IPv6 dual-stack networking
https://cloud.google.com/kubernetes-engine/docs/concepts/alias-ips#dual_stack_network
Step 8 – Resource Provisioning – Compute (Serverless / Function as a Service)
If we have already managed to provision VMs and containers, what about provisioning serverless or Function as a Service?
Let us compare the cloud providers’ alternatives:

Vendor documentation:
- AWS Lambda now supports Internet Protocol Version 6 (IPv6) endpoints for inbound connections
https://aws.amazon.com/about-aws/whats-new/2021/12/aws-lambda-ipv6-endpoints-inbound-connections
Step 9 – Resource Provisioning – Managed Load Balancers
If we are planning to expose services either to the public internet or allow connectivity from our on-premise, we will need to use a managed load-balancer service.
Let us compare the cloud providers’ alternatives:
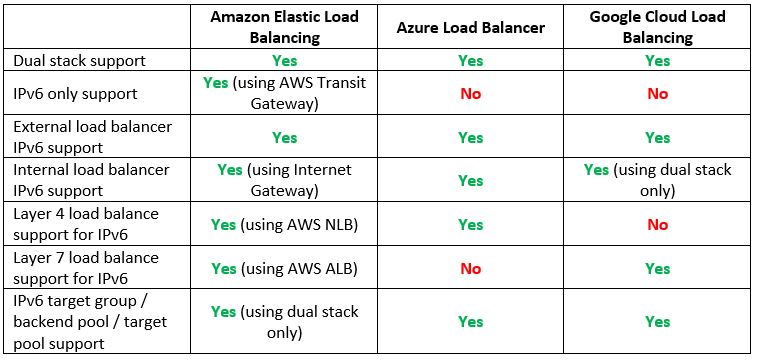
Vendor documentation:
- Application Load Balancer and Network Load Balancer end-to-end IPv6 support
- Overview of IPv6 for Azure Load Balancer
https://learn.microsoft.com/en-us/azure/load-balancer/load-balancer-ipv6-overview
- GCP – IPv6 termination for External HTTP(S), SSL Proxy, and External TCP Proxy Load Balancing
https://cloud.google.com/load-balancing/docs/ipv6
Step 10 – Resource Provisioning – Managed Object Storage
The next step after provisioning compute services is to allow us to store data in an object storage service.
Let us compare the cloud providers’ alternatives:
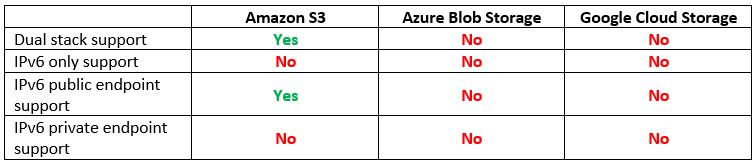
Vendor documentation:
- Making requests to Amazon S3 over IPv6
https://docs.aws.amazon.com/AmazonS3/latest/userguide/ipv6-access.html
Step 11 – Resource Provisioning – Managed Database Services
Most of the application we provision requires a backend database to store and retrieve data.
Let us compare the cloud providers’ alternatives:

Vendor documentation:
- IPv6 addressing with Amazon RDS
https://aws.amazon.com/blogs/database/ipv6-addressing-with-amazon-rds
- Connectivity architecture for Azure SQL Managed Instance – Networking constraints
Step 12 – Protecting Network Access – Managed Firewall Services
If we are planning to expose services to the public Internet using IPv6 or allow access from on-premise, we need to consider a managed network firewall service.
Let us compare the cloud providers’ alternatives:

Vendor documentation:
- AWS Network Firewall announces IPv6 support
https://aws.amazon.com/about-aws/whats-new/2023/01/aws-network-firewall-ipv6-support
Step 13 – Protecting Network Access – Managed DDoS Protection Services
On the topic of exposing services to the public Internet, we need to take into consideration protection against DDoS attacks.
Let us compare the cloud providers’ alternatives:

Vendor documentation:
- AWS Shield FAQs
https://aws.amazon.com/shield/faqs
- About Azure DDoS Protection SKU Comparison
https://learn.microsoft.com/en-us/azure/ddos-protection/ddos-protection-sku-comparison
- Google Cloud Armor – Security policy overview
https://cloud.google.com/armor/docs/security-policy-overview
Step 14 – Protecting Network Access – Managed Web Application Firewall
We know that protection against network-based attacks is possible using IPv6.
What about protection against application-level attacks?
Let us compare the cloud providers’ alternatives:

Vendor documentation:
- IPv6 Support Update – CloudFront, WAF, and S3 Transfer Acceleration
https://aws.amazon.com/blogs/aws/ipv6-support-update-cloudfront-waf-and-s3-transfer-acceleration
- What is Azure Front Door?
https://learn.microsoft.com/en-us/azure/frontdoor/front-door-overview
Summary
In this blog post we have compared various cloud services, intending to answer the question – Is the public cloud ready for IPv6?
As we have seen, many cloud services do support IPv6 today (mostly in dual-stack mode), and AWS does seem to be more mature than its competitors, however, at the time of writing this post, the public cloud is not ready to handle IPv6-only services.
The day we will be able to develop cloud-native applications while allowing end-to-end IPv6-only addresses, in all layers (from the network, compute, database, storage, event-driven / message queuing, etc.), is the day we know the public cloud is ready to support IPv6.
For the time being, dual stack (IPv4 and IPv6) is partially supported by many services in the cloud, but we cannot rely on end-to-end connectivity.
Additional References
- AWS services that support IPv6
https://docs.aws.amazon.com/general/latest/gr/aws-ipv6-support.html
- An Introduction to IPv6 on Google Cloud
https://cloud.google.com/blog/products/networking/getting-started-with-ipv6-on-google-cloud
Introduction to Container Operating Systems
Working with modern computing environments based on containers offers a lot of benefits (from small image footprint, fast deployment/decommission, and more), but it also has its challenges (from software/package update process, security, integration with container orchestrators, and more).
In this blog post, I will review container operating systems, what are their benefits in the modern cloud environment, and how AWS compares to Google Cloud in terms of container operating systems.
What is Container Operating-Systems?
Container OS is a special type of Linux OS, dedicated to running container workloads.
Below are some of the benefits of using Container OS:
- Small OS footprint – Container OS includes only the necessary packages and dependencies for running containers
- Optimized performance – Container OS is optimized specifically to run container workloads
- Immutable root filesystem – The root filesystem is mounted as read-only. No changes can be done to the root filesystem
- Remote control – SSH to the Container OS is disabled by default
- Automatic updates – Container OS software updates are done using the CSP-managed containers or Kubernetes service upgrade mechanisms
AWS Bottlerocket vs. Google Container-Optimized OS
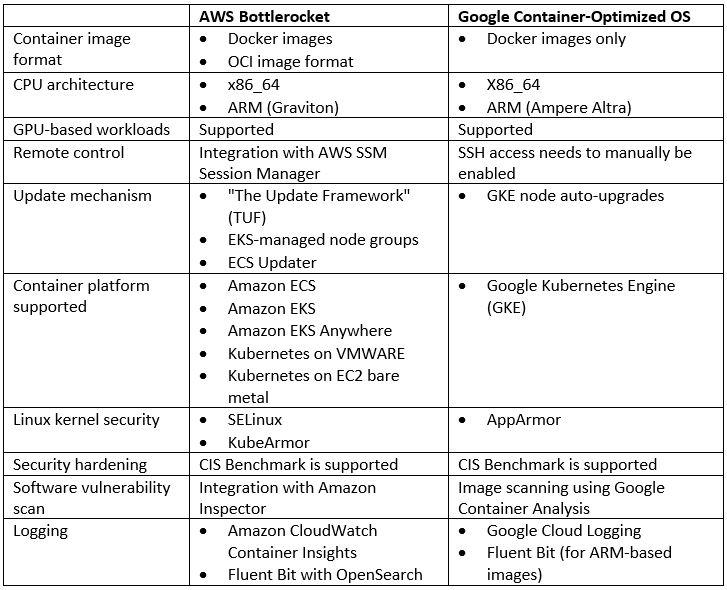
Summary
Container operating systems are considered the last word in the evolution of hypervisors, optimized to run container workloads.
Their small footprint, built-in security features, auto-update, and integration with managed Kubernetes services make them idle for running container workloads.
Although both Bottlerocket and Container-Optimized OS were created by specific cloud providers, AWS Bottlerocket does offer much broader alternatives for running a container OS on various container platforms.
References
- AWS Bottlerocket
https://aws.amazon.com/bottlerocket/
- Google Container-Optimized OS
Cloud Native Applications – Part 2: Security

In chapter 1 of this series about cloud-native applications, we have introduced the key characteristics of cloud-native applications.
In this chapter, we will review how to secure cloud-native applications.
Securing the CI/CD pipeline
Due to the dynamic nature of the cloud-native application, we need to begin securing our application stack from the initial steps of the CI/CD pipeline.
Since I have already written posts on how to secure DevOps processes, automation, and supply chain, I will highlight the following:
- Run code analysis using automated tools (SAST – Static application security tools, DAST – Dynamic application security tools)
- Run SCA (Software composition analysis) tool to detect known vulnerabilities in open-source binaries and libraries
- Sign your software package before storing them in a repository
- Store all your sources (code, container images, libraries) in a private repository, protected by strong authorization mechanisms
- Invest in security training for developers, DevOps, and IT personnel
- Make sure no human access is allowed to production environments (use Break Glass accounts for emergency purposes)
Additional references:
- Integrate security aspects in a DevOps process
- Securing the Software Supply Chain in the Cloud
- Cloud Native Security Map
Securing infrastructure build process
As I have mentioned in the previous chapter of this series, one of the characteristics of cloud-native applications is the fact that it is built using Infrastructure as Code.
Each cloud provider has its own IaC scripting language, and naturally, there is cloud agnostic (or multi-cloud…) – HashiCorp Terraform.
Since this is code, we need to store the code in a private repository and scan the code for security vulnerabilities, but we need an additional layer of protection for Infrastructure as Code.
This is referred to as Policy as Code, where we can define a set of controls, from enforcing encryption at transit and rest, enabling resource provisioning on specific regions, or prohibiting the creation of instances with public IP.
The next thing in terms of the policy as code is called OPA – Open Policy Agent. It supports all major cloud providers and has built-in integration with Terraform, Kubernetes, and more.
OPA has its declarative language called Rego and it can integrate inside an existing CI/CD pipeline.
Additional references:
- Introduction to Policy as Code
- Automation as key to cloud adoption success
- Open Policy Agent
- Terraform OPA policies examples
Securing Containers / Kubernetes
Containers are one of the most common ways to package and deploy modern applications, and as a result, we need to secure the containerized environment.
It begins with a minimum number of binaries and libraries inside a container image.
We must make sure we scan our container images for vulnerable binaries or open-source libraries, and eventually, we need to store our container images inside a private container registry.
In most cases, when using Kubernetes as an orchestrator, we should choose a managed Kubernetes service (offered by each of the major cloud providers).
Using a Kubernetes control plane based on a managed service shifts the responsibility for securing and maintaining the Kubernetes control plane on the cloud provider.
One thing to keep in mind – we should always create private clusters, and make sure the control plane is never accessible outside our private subnets, to reduce the attack surface on our Kubernetes cluster.
In terms of authorization, we should follow the principle of least privilege and use RBAC (Role-based access control), to allow our application to function and our developers or support team the minimum number of required permissions to do their job.
In terms of network connectivity to and between pods, we should use one of the service mesh solutions (such as Istio), and set network policies that clearly define which pod can communicate with which pod, and who can access the API server.
In terms of secrets management that the containers need access to, we need to make sure all sensitive data (secrets, credentials, API keys, etc.) are stored in a secured location (such as AWS Secrets Manager, Azure Key Vault, Google Secret Manager, Oracle Cloud Infrastructure Vault or HashiCorp Vault), where all requests to pull a secret are authorized and audited, and secrets can automatically rotate.
Additional references:
- Kubernetes security
- Overview of Cloud Native Security
- OWASP – Kubernetes Security Cheat Sheet
- CIS Benchmark for Kubernetes
- The Istio service mesh
Securing APIs
As we have mentioned in the previous chapter, communication between containers is done using APIs. Also, when communicating with applications deployed inside pods as part of the Kubernetes cluster, all communication is done through the Kubernetes API server.
Not to mention that modern applications, websites and naturally mobile applications are exposing APIs to customers from the public internet (unless your application is meant for private use only…).
Below are the main best practices for securing APIs:
- Authentication – make sure all your APIs require authentication. Regardless if your API is supposed to share public stock exchange data, a retail book catalog, or weather statistics, all requests to pull data from an exposed API must be authenticated.
- Authorization – make sure you set strict access control on each API request, whether it is read data from a database, update records, or privileged actions such as deleting data. Keep in mind the principle of least privilege.
- Encryption – all traffic to an exposed API must be encrypted at transit using the most up-to-date encryption protocol (for example TLS 1.2 or above). Encryption keeps the data confidential and proves the identity of your API (or server) to your customers.
- Auditing – make sure all actions done on your APIs are auditing and all logs are sent to a central logging system (or SIEM) for further archive and analysis (to find out if someone is trying to take actions they are not supposed to).
- Input validation – make sure all input coming to your APIs is been validated, before storing it in a backend database. It will allow you to limit the chance of injection attacks.
- DDoS and web-related attacks – make sure all your exposed APIs are protected behind anti-DDoS and behind a web application firewall. If it will not block 100% of the attacks, at least you will be able to block the well-known and signature-based attacks and decrease the amount of unwanted traffic against your APIs.
- Code review – API is a piece of code. Before pushing new changes to any API, make sure you run static and dynamic code analysis, to locate security vulnerabilities embed in your code.
- Throttling – make sure you enforce a throttling mechanism, in case someone tries to access your API multiple times from the same source, to avoid a situation where your API is unavailable for all your customers.
Additional reference:
Authorization
Authorization in a cloud-native application can be challenging.
On legacy applications all components were built as part of a single monolith, users had to log in from a single-entry point, and once we have authenticated and authorized them, they were to access data and with proper permissions to make changes to data as well.
Since modern applications are built upon micro-service architecture, we need to think not just about end users communicating with our application, but also about how each component in our architecture is going to communicate with other components (such as pod-to-pod communication required authorization).
If every component in our entire application is developed by a separate team, we need to think about a central authorization mechanism.
But central authorization mechanism is not enough.
We need to integrate our authorization mechanism with a central IAM (Identity and Access Management) system.
I would not recommend to re-invent the wheel – try to use the IAM service from your cloud provider of choice. Cloud-native IAM systems have built-in integration with the cloud eco-system, including auditing capabilities – this way you will be able to consume the service, without maintaining the underlining infrastructure.
Checking the end-users’ privileges at login time might not be sufficient. We need to think about fine-grain permissions – is a generic “Reader user” enough? Do the user needs read access to all data stored in our data store? Perhaps he only needs read access to a specific line of business customers database and nothing more. Always keep in mind the principle of least privilege.
Our authorization mechanism needs to be dynamic according to each request and data the user is trying to access, be verified constantly and allow us to easily revoke permissions in case of suspicious activity, when permissions are no longer needed or if data confidentially has changed over time.
We need to make sure our authorization mechanism can be easily integrated and consumed by each of the various development groups, as a standard authorization mechanism.
Additional references:
Summary
In this post, we have reviewed various topics we need to take into consideration when talking about how to secure cloud-native applications.
We have reviewed the highlights of securing the build process, the infrastructure provisioning, Kubernetes (as an orchestrator engine to run our applications), and not forgetting topics that are part of the secure development lifecycle (securing APIs and authorization mechanism).
Naturally, we have just covered some of the highlights of security in cloud-native applications.
I strongly recommend you to deep dive into each topic, read the references and search for additional information that will allow any developer, DevOps, DevSecOps, architect, or security professional, to better secure cloud-native applications.
Additional References:
Cloud Native Applications – Part 1: Introduction

In the past couple of years, there is a buzz about cloud-native applications.
In this series of posts, I will review what exactly is considered a cloud-native application and how can we secure cloud-native applications.
Before speaking about cloud-native applications, we should ask ourselves – what is cloud native anyway?
The CNCF (Cloud Native Computing Foundation) provides the following definition:
“Cloud native technologies empower organizations to build and run scalable applications in modern, dynamic environments such as public, private, and hybrid clouds. Containers, service meshes, microservices, immutable infrastructure, and declarative APIs exemplify this approach.
These techniques enable loosely coupled systems that are resilient, manageable, and observable. Combined with robust automation, they allow engineers to make high-impact changes frequently and predictably with minimal toil.”
Source: https://github.com/cncf/toc/blob/main/DEFINITION.md
It means – taking full advantage of cloud capabilities, from elasticity (scale in and scale out according to workload demands), use of managed services (such as compute, database, and storage services), and the use of modern design architectures based on micro-services, APIs, and event-driven applications.
What are the key characteristics of cloud-native applications?
Use of modern design architecture
Modern applications are built from loosely coupled architecture, which allows us to replace a single component of the application, with minimal or even no downtime to the entire application.
Examples can be code update/change or scale in/scale out a component according to application load.
- RESTful APIs are suitable for communication between components when fast synchronous communication is required. We use API gateways as managed service to expose APIs and control inbound traffic to various components of our application.
Example of services:
- Amazon API Gateway
- Azure API Management
- Google API Gateway
- Oracle API Gateway
- Event-driven architecture is suitable for asynchronous communication. It uses events to trigger and communicate between various components of our application. In this architecture, one component produces/publishes an event (such as a file uploaded to object storage) and another component subscribes/consumes the events (in a Pub/Sub model) and reacts to the event (for example reads the file content and steam it to a database). This type of architecture handles load very well.
Example of services:
- Amazon EventBridge
- Amazon Simple Queue Service (SQS)
- Azure Event Grid
- Azure Service Bus
- Google Eventarc
- Google Cloud Pub/Sub
- Oracle Cloud Infrastructure (OCI) Events Service
Additional References:
- AWS – What is API management?
- AWS – What is an Event-Driven Architecture?
- Azure – API Design
- Azure – Event-driven architecture style
- Google API design guide
- GCP – Event-driven architectures
- Oracle API For Developers
- Oracle Cloud – Modern App Development – Event-Driven
Use of microservices
Microservices represent the concept of distributed applications, and they enable us to decouple our applications into small independent components.
Components in a microservice architecture usually communicate using APIs (as previously mentioned in this post).
Each component can be deployed independently, which provides a huge benefit for code change and scalability.
Additional references:
- AWS – What are Microservices?
- Azure – Microservice architecture style
- GCP – What is Microservices Architecture?
- Oracle Cloud – Design a Microservices-Based Application
- The Twelve-Factor App
Use of containers
Modern applications are heavily built upon containerization technology.
Containers took virtual machines to the next level in the evolution of computing services.
They contain a small subset of the operating system – only the bare minimum binaries and libraries required to run an application.
Containers bring many benefits – from the ability to run anywhere, small footprint (for container images), isolation (in case of a container crash), fast deployment time, and more.
The most common orchestration and deployment platform for containers is Kubernetes, used by many software development teams and SaaS vendors, capable of handling thousands of containers in many production environments.
Example of services:
- Amazon Elastic Kubernetes Service (EKS)
- Azure Kubernetes Service (AKS)
- Google Kubernetes Engine (GKE)
- Oracle Container Engine for Kubernetes (OKE)
Additional References:
Use of Serverless / Function as a Service
More and more organizations are beginning to embrace serverless or function-as-a-service technology.
This is considered the latest evolution in computing services.
This technology allows us to write code and import it into a managed environment, where the cloud provider is responsible for the maintenance, availability, scalability, and security of the underlining infrastructure used to run our code.
Serverless / Function as a Service, demonstrates a very good use case for event-driven applications (for example – an event written to a log file triggers a function to update a database record).
Functions can also be part of a microservice architecture, where some of the application components are based on serverless technology, to run specific tasks.
Example of services:
Additional References:
- Serverless on AWS
- Azure serverless
- Google Cloud Serverless computing
- Oracle Cloud – What is serverless?
Use of DevOps processes
To support rapid application development and deployment, modern applications use CI/CD processes, which follow DevOps principles.
We use pipelines to automate the process of continuous integration and continuous delivery or deployment.
The process allows us to integrate multiple steps or gateways, where in each step we can embed additional automated tests, from static code analysis, functional test, integration test, and more.
Example of services:
Additional References:
Use of automated deployment processes
Modern application deployment takes an advantage of automation using Infrastructure as Code.
Infrastructure as Code is using declarative scripting languages, in in-order to deploy an entire infrastructure or application infrastructure stack in an automated way.
The fact that our code is stored in a central repository allows us to enforce authorization mechanisms, auditing of actions, and the ability to roll back to the previous version of our Infrastructure as Code.
Infrastructure as Code integrates perfectly with CI/CD processes, which enables us to re-use the knowledge we already gained from DevOps principles.
Example of solutions:
Additional References:
- Automation as key to cloud adoption success
- AWS – Infrastructure as Code
- Azure – What is infrastructure as code (IaC)?
- Want a repeatable scale? Adopt infrastructure as code on GCP
- Oracle Cloud – What Is Infrastructure as Code (IaC)?
Summary
In this post, we have reviewed the key characteristics of cloud-native applications, and how can we take full advantage of the cloud, when designing, building, and deploying modern applications.
I recommend you continue expanding your knowledge about cloud-native applications, whether you are a developer, IT team member, architect, or security professional.
Stay tuned for the next chapter of this series, where we will focus on securing cloud-native applications.
Additional references
Mitigating the risk of a cloud outage or lack of cloud resources

Organizations migrating to the public cloud, or already provisioning workloads in the cloud come across limitations, either on production workloads or issues published in the media, as you can read below:


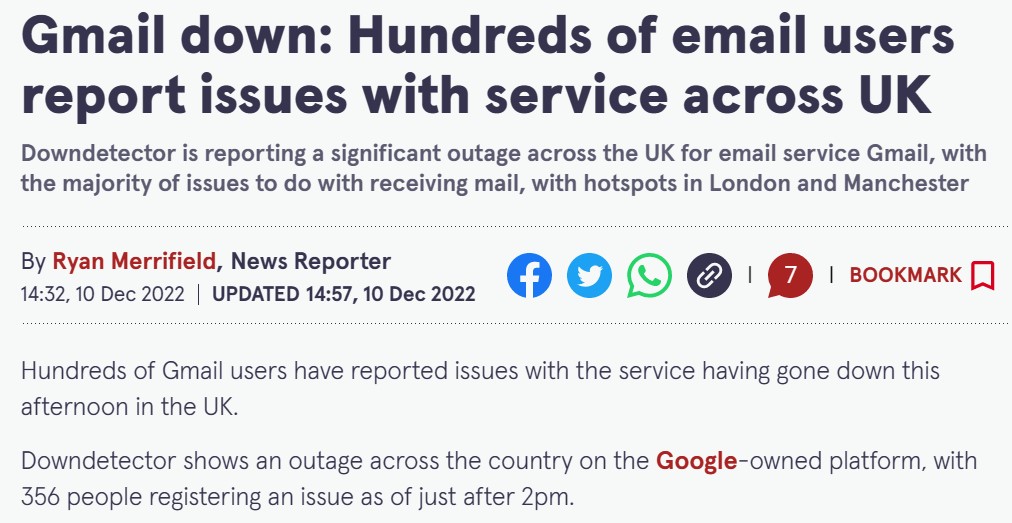

As a cloud consumer, you might be asking yourself, how do I mitigate such risks from affecting my production workloads? (Assuming your organization has already invested a lot of money and resources in the public cloud)
There is no one answer to this question, but in the following post, I will try to review some of the alternatives for protecting yourself or at least try to mitigate the risks.
Alternative 1 – Switching to a cloud-native application
This alternative takes full advantage of cloud benefits.
Instead of using VMs to run or process your workload, you will have to re-architect your application and use cloud-native services such as Serverless / Function as Service, managed services (from serverless database services, object storage, etc.), and event-driven services (such as Pub/Sub, Kafka, etc.)
Pros
- You decrease your application dependencies on virtual machines (on-demand, reserved instances, and even Spot instances), so resource allocation limits of VMs should be less concerning.
Cons
- Full re-architecture of your applications can be an expensive and time-consuming process. It requires a deep review of the entire application stack, understanding the application requirements and limitations, and having an experienced team of developers, DevOps, architects, and security personnel, knowledgeable enough about your target cloud providers ecosystem.
- The more you use a specific cloud’s ecosystem (such as proprietary Serverless / Function as a Service), the higher your dependency on specific cloud technology, which will cause challenges in case you are planning to switch to another cloud provider sometime in the future (or consider the use of multi-cloud).
Additional references:
- AWS – What Is Cloud Native?
- Azure – What is Cloud Native?
- Google Cloud – What is cloud-native?
- Oracle Cloud – What is Cloud Native?
Alternative 2 – The multi-region architecture
This alternative suggests designing a multi-region architecture, where you use several (separate) regions from your cloud provider of choice.
Pros
- The use of multi-region architecture will decrease the chance of having an outage of your services or the chance of having resource allocation issues.
Cons
- In case the cloud provider fails to create a complete separation between his regions (see: https://www.theguardian.com/technology/2020/dec/14/google-suffers-worldwide-outage-with-gmail-youtube-and-other-services-down), multi-region architecture will not resolve potential global outage issues (or limit the blast radius).
- In case you have local laws or regulations which force you to store personal data on data centers in a specific jurisdiction, a multi-region solution is not an option.
- Most IaaS / PaaS services offered today by cloud providers are regional, meaning, they are limited to a specific region and do not span across regions, and as a result, you will have to design a plan for data migration or synchronization across regions, which increases the complexity of maintaining this architecture.
- In a multi-region architecture, you need to take into consideration the cost of egress data between separate regions.
Additional references:
- AWS – Multi-Region Application Architecture
- Azure – Multi-region N-tier application
- Google Cloud – Creating multi-region deployments for API Gateway
- Oracle Cloud – Implementing a high-availability architecture in and across regions
- Using the Cloud to build multi-region architecture
Alternative 3 – Cloud agnostic architecture (or preparation for multi-cloud)
This alternative suggests using services that are available for all major cloud providers.
An example can be – to package your application inside containers and manage the containers orchestration using a Kubernetes-managed service (such as Amazon EKS, Azure AKS, Google GKE, or Oracle OKE).
To enable cloud agnostic architecture from day 1, consider provisioning all resources using HashiCorp Terraform – both for Kubernetes resources and any other required cloud service, with the relevant adjustments for each of the target cloud providers.
Pros
- Since container images can be stored in a container registry of your choice, you might be able to migrate between cloud providers.
Cons
- Using Kubernetes might resolve the problem of using the same underlining orchestrator engine, but you will still need to think about the entire cloud provider ecosystem (from data store services, queuing services, caching, identity authentication and authorization services, and more.
- In case you have already invested a lot of resources in a specific cloud provider and already stored a large amount of data in a specific cloud provider’s storage service, migrating to another cloud provider will be an expensive move, not to mention the cost of egress data between different cloud providers.
- You will have to invest time in training your teams on working with several cloud providers’ infrastructures and maintain several copies of your Terraform code, to suit each cloud provider infrastructure.
Summary
Although there is no full-proof answer to the question “How do I protect myself from the risk of a cloud outage or lack of cloud resources”, we need to be aware of both types of risks.
We need to be able to explain the risks and the different alternatives provided in this post and explain them to our organization’s top management.
Once we understand the risks and the pros and cons of each alternative, our organization will be able to decide how to manage the risk.
I truly believe that the future of IT is in the public cloud, but migrating to the cloud blindfolded, is the wrong way to fully embrace the potential of the public cloud.
Securing the software supply chain in the cloud

The software supply chain is considered one of the common threats in today’s modern cloud-native development, which poses a high risk to any organization.
It is about consuming software packages, source code, or even APIs from a third-party or untrusted source.
The last thing we wish to do is to block developers from building new applications, but we need to understand the threats to the software supply chain.
What are the common threats?
There are a couple of common threats that can arise from a software supply chain attack:
- Ransomware – An example is the NotPetya malware and Maersk
- Data breach – An example is the Okta Hack
- Backdoor – An example is the SolarWinds backdoor
- Access to private data – An example is the GitHub OAuth tokens attack
- API vulnerabilities – An example is the BOLA (Broken Object Level Authorization)
As we can see, most supply chain attacks begin with a download of an untrusted piece of code, which leads to malware infection, or pulling data from an external API, which inserts unverified data into a backend system.
Steps to mitigate the risk of supply chain attacks
The modern development lifecycle is based on CI/CD (Continuous Integration / Continuous Deployment or Delivery), we can embed security gates at various stages of the CI/CD pipeline, as explained below.
Source Code
- Scan for software vulnerabilities (such as binaries and open-source libraries), before storing components/code/libraries inside VM or container images inside an image repository.
Example of services:
- Amazon Inspector – Vulnerability scanner for Amazon EC2, container images (inside Amazon ECR), and Lambda functions
- Microsoft Defender for Containers – Vulnerability scanner for containers
- Google Container Analysis – Vulnerability scanner for containers
- Scan your code stored in your repositories, to make sure it does not contain sensitive data (such as secrets, API keys, credentials, etc.)
Example of tools:
- git-secrets
- Gitleaks
- SecretScanner
- Run static code analysis on any developed or imported code, to search for vulnerabilities.
Example of tools:
- Snyk – Scan for open-source, code, container, and Infrastructure-as-Code vulnerabilities
- Trivy – Scan for open-source, code, container, and Infrastructure-as-Code vulnerabilities
- Chekov – Scan for open-source and Infrastructure-as-Code vulnerabilities
- KICS – Scan for Infrastructure-as-Code vulnerabilities
- Terrascan – Scan for Infrastructure-as-Code vulnerabilities
- Kubescape – Scan for Kubernetes vulnerabilities
- Scan your binaries to verify their trustworthiness – especially important when you import binaries from an external source.
Example of services:
Repositories
- Create a private repository for storing source code, VM images, or container images
- Enforce authentication and authorization for who can access and make changes to the repository
- Sign all source code/images stored in the repository
- Audit access to the repositories
Example of services for storing source code:
Example of services for storing VM images:
Example of services for storing container images:
Example of service for storing serverless code:
Authentication & Authorization
- Configure authentication and authorization process (who has written permissions to the repository), and enforce the use of MFA.
Example of services:
- AWS Identity and Access Management (IAM)
- Azure Active Directory (Azure AD)
- Google Cloud Identity and Access Management (IAM)
- Store all sensitive data (such as secrets, credentials, API keys, etc.) in a secured vault, enforce key rotation, and access management to keys.
Example of services:
Handling data from external APIs
There are many cases where we rely on data from external third parties, exposed using APIs.
Since we cannot verify the trustworthiness of external data, we must follow the following guidelines:
- Never rely on unauthenticated APIs – always make sure the connectivity to the external APIs requires proper authentication (such as certificates, rotated API key, etc.) and proper
- Always make sure the remote API enforces proper authorization mechanism – if the remote API allows admin or even write access to anyone on the Internet, the data it provides is not considered trusted anymore
- Always make sure data is encrypted at transit – it allows to keep data confidentiality and provides a high degree of trust in the remote endpoint
- Always perform input validation and proper escaping, before storing data from an external source into any backend database
For further reading, see:
Summary
In the post, we have reviewed threats as a result of software supply chain vulnerabilities, and various tools and services that can assist us in securing the modern development process of cloud-native applications.
It is possible to mitigate the risks coming from the software supply chain, whether it is code that we develop in-house or code/binaries/libraries that we import from a third-party source, but we must always follow the concept of “Trust but verify”.
References
- Build your secure software supply chains on AWS
- Supply Chain Security on Amazon Elastic Kubernetes Service (Amazon EKS) using AWS Key Management Service (AWS KMS), Kyverno, and Cosign
- Best practices for a secure software supply chain
- Monitoring the Software Supply Chain with Azure Sentinel
- Software supply chain security
- Perspectives on Security – Securing Software Supply Chains
- NIST – Defending Against Software Supply Chain Attacks
- CNCF Software Supply Chain Best Practices
