Archive for the ‘AWS’ Category
Identity and Access Management in Multi-Cloud Environments

IAM (Identity and Access Management) is a crucial part of any cloud environment.
As organizations evolve, they may look at multi-cloud as a solution to consume cloud services in different cloud providers’ technologies (such as AI/ML, data analytics, and more), to have the benefit of using different pricing models, or to decrease the risk of vendor lock-in.
Before we begin the discussion about IAM, we need to understand the following fundamental concepts:
- Identity – An account represents a persona (human) or service (non-interactive account)
- Authentication – The act where an identity proves himself against a system (such as providing username and password, certificate, API key, and more)
- Authorization – The act of validating granting an identity’s privileges to take actions on a system (such as view configuration, read database content, upload a file to object storage, and more)
- Access Management – The entire lifecycle of IAM – from account provisioning, granting access, and validating privileges until account or privilege revocation.
Identity and Access Management Terminology
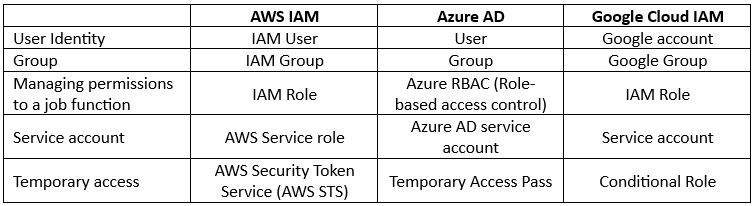
Authorization in the Cloud
Although all cloud providers have the same concept of identities, when we deep dive into the concept of authorization or access management to resources/services, we need to understand the differences between cloud providers.
Authorization in AWS
AWS has two concepts for managing permissions to resources:
- IAM Role – Permissions assigned to an identity temporarily.
- IAM Policy – A document defines a set of permissions assigned to an IAM role.
Permissions in AWS can be assigned to:
- Identity – A policy attached to a user, group, or role.
- Resource – A policy attached to a resource (such as Amazon S3 bucket).
Authorization in Azure
Permissions in Azure AD are controlled by roles.
A role defines the permissions an identity has over an Azure resource.
Within Azure AD, you control permissions using RBAC (Role-based access control).
Azure AD supports the following types of roles:
- Built-in roles – A pre-defined role according to job function (as you can read on the link).
- Custom roles – A role that we create ourselves to match the principle of least privilege.
Authorization in Google Cloud
Permissions in Google Cloud IAM are controlled by IAM roles.
Google Cloud IAM supports the following types of IAM roles:
- Basic roles – The most permissive type of roles (Owner, Editor, and Viewer).
- Predefined roles – Roles managed by Google, which provides granular access to specific services (as you can read on the link).
- Custom roles – User-specific roles, which provide the most granular access to resources.
Authorization – Default behavior
As we can see below each cloud provider takes a different approach to default permissions:
- AWS – By default, new IAM users have no permission to access any resource in AWS.
To allow access to resources or take actions, you need to manually assign the user an IAM role. - Azure – By default, all Azure AD users are granted a set of default permissions (such as listing all users, reading all properties of users and groups, registering new applications, and more).
- Google Cloud – By default, a new service account is granted the Editor role on the project level.
Identity Federation
When we are talking about identity federation, there are two concepts:
- Service Provider (SP) – Provide access to resources
- Identity Provider (IdP) – Authenticate the identities
Identities (user accounts, service accounts, groups, etc.) are managed by an Identity Provider (IdP).
An IdP can exist in the local data center (such as Microsoft Active Directory) or the public cloud (such as AWS IAM, Azure AD, Google Cloud IAM, etc.)
Federation is the act of creating trust between separate IdP’s.
Federation allows us to keep identity in one repository (i.e., Identity Provider).
Once we set up an identity federation, we can grant an identity privilege to consume resources in a remote repository.
Example: a worker with an account in Microsoft Active Directory, reading a file from object storage in Azure, once a federation trust was established between Microsoft Active Directory and Azure Active Directory.
When federating between the on-premise and cloud environments, we need to recall the use of different protocols.
On-premise environments are using legacy authentication protocols such as Kerberos or LDAP.
In the public cloud, the common authentication protocols are SAML 2.0, Open ID Connect (OIDC), and OAuth 2.0
Each cloud provider has a list of supported external third-party identity providers to federate with, as you can read in the list below:
- Integrating third-party SAML solution providers with AWS
- Azure AD Identity Provider Compatibility Docs
- Google Cloud IAM – Configure workforce identity federation
Single Sign-On
The concept behind SSO is to allow identities (usually end-users) access to resources in the cloud while having to sign (to an identity provider) once.
Over the past couple of years, the concept of SSO was extended and now it is possible to allow a single identity (who authenticated to a specific identity provider), access to resources over federated login to an external (mostly SAML) identity provider.
Each cloud provider has its own SSO service, supporting federation with external identity providers:
- AWS IAM Identity Center
- Azure Active Directory single sign-on
- Google Cloud Workload identity federation
Steps for creating a federation between cloud providers
The process below explains (at a high level) the steps require to set up identity federation between different cloud providers:
- Choose an IdP (where identities will be created and authenticated to).
- Create a SAML identity provider.
- Configure roles for your third-party identity provider.
- Assign roles to the target users.
- Create trust between SP and IdP.
- Test the ability to authenticate and identify (user) to a resource in a remote/external cloud provider.
Additional References:
- AWS IAM Identity Center and Azure AD as IdP
- How to set up IAM federation using Google Workspace
- Azure AD SSO integration with AWS IAM Identity Center
- Azure AD SSO integration with Google Cloud / G Suite Connector by Microsoft
- Federating Google Cloud with Azure Active Directory
- Configure Google workload identity federation with AWS or Azure
Summary
In this blog post, we had a deep dive into identity and access management in the cloud, comparing different aspects of IAM in AWS, Azure, and GCP.
After we have reviewed how authentication and authorization work for each of the three cloud providers, we have explained how federation and SSO work in a multi-cloud environment.
Important to keep in mind:
When we are building systems in the cloud, whether they are publicly exposed or even internal, we need to follow some basic rules:
- All-access to resources/systems/applications must be authenticated
- Permissions must follow the principle of least privileged and business requirements
- All access must be audited (for future analysis, investigation purposes, etc.)
Introduction to AWS Resilience Hub

When deploying a new application in the public cloud, we need to ask the business owner what are the resiliency (or SLA) requirements – How long can the business survive while our application is down and does not serve customers?
There are various answers to that question – from 24/7 availability (not realistic) to uptime of 99.9%, etc.
The domain of resiliency has two main concepts:
- RTO (Recovery Time Objective) – the amount of time it takes to recover a system after disruption
- RPO (Recovery Point Objective) – the amount of data loss, measured by time
To achieve high resiliency, or follow business SLA requirements, there are technical and cost consequences.
Naturally, we want to provision resources in high-availability (such as a farm of front-end web servers behind load-balancer), in a cluster (such as a cluster of database instances), deployed in multiple availability zones or perhaps in multiple regions, and try to avoid single point of failure.
We need to plan an architecture that will support our business resiliency requirements.
In theory, an architect can look at proposed architecture and say whether or not he sees potential availability failures, but it does not scale in large and complex architectures.
In 2021, AWS announced the general availability of the AWS Resilience Hub.
In this blog post, I will review what is the purpose of this service and how can we use it regularly, as part of our CI/CD process.
How does AWS Resilience Hub work?
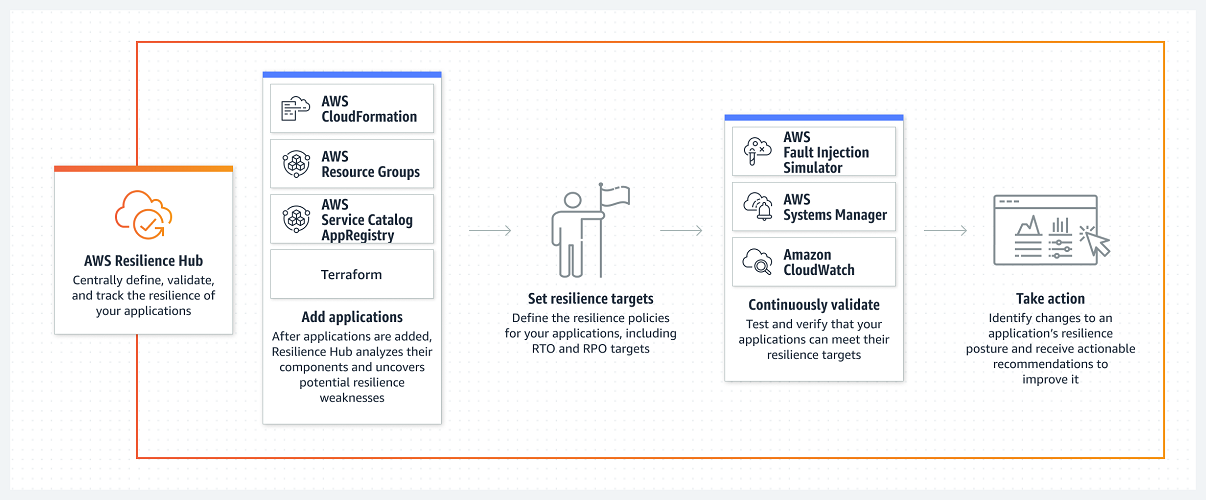
Source: https://docs.aws.amazon.com/resilience-hub/latest/userguide/how-it-works.html
To work with AWS Resilience Hub, follow the steps below:
Add an application
AWS Resilience Hub allows you to assess an application by scanning the following resources:
- AWS Resource Groups
- AWS AppRegistry applications
- AWS CloudFormation stacks
- Terraform state files
- Amazon EKS cluster configuration
Set resilience targets
AWS Resilience Hub supports the following built-in tiers:
- Foundational IT core services
- Mission critical
- Critical
- Important
- Non-critical
Choose the target policy according to the application business requirements of RTO and RPO.
Select one of the predefined suggested policies:
- Non-critical application
- Important Application
- Critical Application
- Global Critical Application
- Mission Critical Application
- Global Mission Critical Application
- Foundational Core Service
AWS Resilience Hub allows you to evaluate the resiliency of an application against the following types of disruption:
- Customer Application RTO and RPO
- AWS Infrastructure RTO and RPO
- Cloud Infrastructure Availability Zone (AZ) disruption
- AWS Region disruption
Run an assessment
AWS Resilience Hub allows you to either run manual on-time assessments or schedule an assessment daily.
To get the most value from AWS Resilience Hub, you can integrate it as part of a CI/CD pipeline, as an additional step, once you provision Infrastructure as Code (using CloudFormation templates or Terraform modules).
A common example of integration with CI/CD pipeline:
In a mature environment, you can take one step further and integrate AWS Resilience Hub with the built-in chaos engineering service AWS Fault Injection Simulator to conduct controlled experiments on your application and evaluate its resiliency.
Review results and continue improvements
Once an assessment was completed, it is time to review the results, to make sure your application meets the business resiliency requirements (in terms of RTO/RPO).
The results will be written in a report, with recommendations for improvements to your application resiliency, such as adding another node to an RDS cluster, deploying another EC2 instance in another availability zone, enabling S3 bucket versioning, etc.
To make things easy to understand and improve over time, you can build dashboards using Amazon QuickSight and send alerts using CloudWatch, as explained in the blog post:
https://aws.amazon.com/blogs/mt/resilience-reporting-dashboard-aws-resilience-hub/
For continuous and automated improvement, you can integrate AWS Resilience Hub with AWS Systems Manager to efficiently recover your application in the event of outages, as explained in the blog post:
https://docs.aws.amazon.com/resilience-hub/latest/userguide/create-custom-ssm-doc.html
Summary
In this blog post, we learned about the purpose of AWS Resilience Hub, what are the various steps for using it, and perhaps most important – how to automate the assessment as part of a CI/CD pipeline for continuous improvement.
I encourage anyone who builds applications on top of AWS to learn about the benefits of this service, providing insights into the resiliency of applications to meet business requirements.
Additional References:
Introduction to Chaos Engineering

In the past couple of years, we hear the term “Chaos Engineering” in the context of cloud.
Mature organizations have already begun to embrace the concepts of chaos engineering, and perhaps the most famous use of chaos engineering began at Netflix when they developed Chaos Monkey.
To quote Werner Vogels, Amazon CTO: “Everything fails, all the time”.
What is chaos engineering and what are the benefits of using chaos engineering for increasing the resiliency and reliability of workloads in the public cloud?
What is Chaos Engineering?
“Chaos Engineering is the discipline of experimenting on a system to build confidence in the system’s capability to withstand turbulent conditions in production.” (Source: https://principlesofchaos.org)
Production workloads on large scale, are built from multiple services, creating distributed systems.
When we design large-scale workloads, we think about things such as:
- Creating high-available systems
- Creating disaster recovery plans
- Decreasing single point of failure
- Having the ability to scale up and down quickly according to the load on our application
One thing we usually do not stop to think about is the connectivity between various components of our application and what will happen in case of failure in one of the components of our application.
What will happen if, for example, a web server tries to access a backend database, and it will not be able to do so, due to network latency on the way to the backend database?
How will this affect our application and our customers?
What if we could test such scenarios on a live production environment, regularly?
Do we trust our application or workloads infrastructure so much, that we are willing to randomly take down parts of our infrastructure, just so we will know the effect on our application?
How will this affect the reliability of our application, and how will it allow us to build better applications?
History of Chaos Engineering
In 2010 Netflix developed a tool called “Chaos Monkey“, whose goal was to randomly take down compute services (such as virtual machines or containers), part of the Netflix production environment, and test the impact on the overall Netflix service experience.
In 2011 Netflix released a toolset called “The Simian Army“, which added more capabilities to the Chaos Monkey, from reliability, security, and resiliency (i.e., Chaos Kong which simulates an entire AWS region going down).
In 2012, Chaos Monkey became an open-source project (under Apache 2.0 license).
In 2016, a company called Gremlin released the first “Failure-as-a-Service” platform.
In 2017, the LitmusChaos project was announced, which provides chaos jobs in Kubernetes.
In 2019, Alibaba Cloud announced ChaosBlade, an open-source Chaos Engineering tool.
In 2020, Chaos Mesh 1.0 was announced as generally available, an open-source cloud-native chaos engineering platform.
In 2021, AWS announced the general availability of AWS Fault Injection Simulator, a fully managed service to run controlled experiments.
In 2021, Azure announced the public preview of Azure Chaos Studio.
What exactly is Chaos Engineering?
Chaos Engineering is about experimentation based on real-world hypotheses.
Think about Chaos Engineering, as one of the tests you run as part of a CI/CD pipeline, but instead of a unit test or user acceptance test, you inject controlled faults into the system to measure its resiliency.
Chaos Engineering can be used for both modern cloud-native applications (built on top of Kubernetes) and for the legacy monolith, to achieve the same result – answering the question – will my system or application survive a failure?
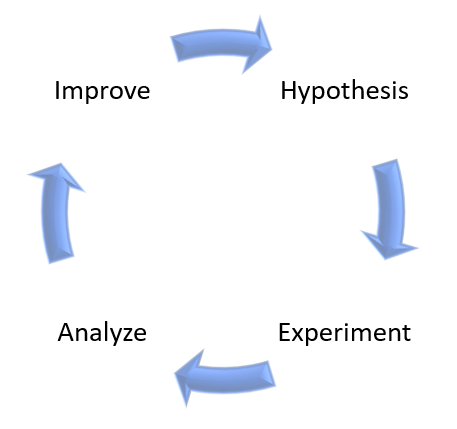
On high-level, Chaos Engineering is made of the following steps:
- Create a hypothesis
- Run an experiment
- Analyze the results
- Improve system resiliency
As an example, here is AWS’s point of view regarding the shared responsibility model, in the context of resiliency:
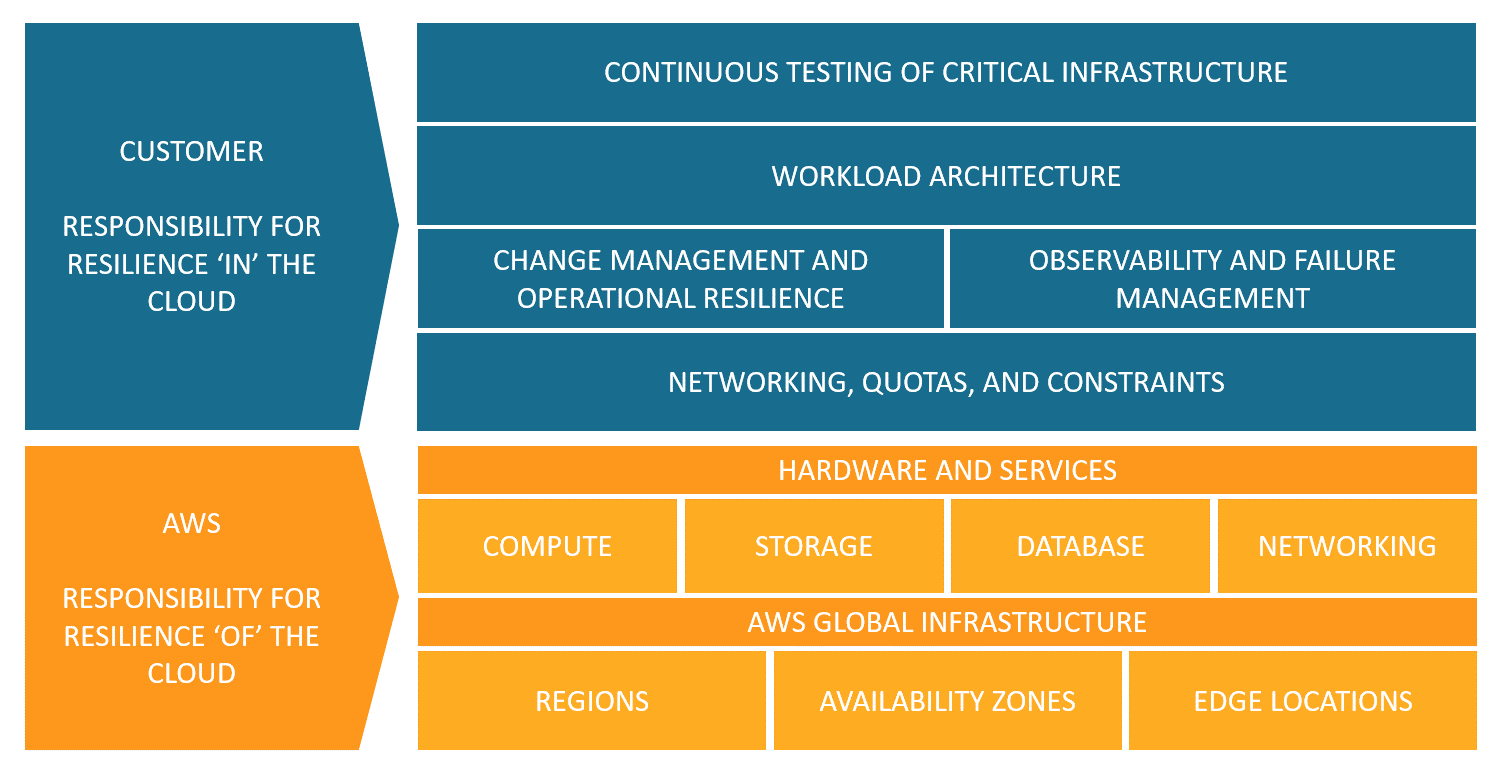
Source: https://aws.amazon.com/blogs/architecture/chaos-engineering-in-the-cloud
Chaos Engineering managed platform comparison
In the table below we can see a comparison between AWS and Azure-managed services for running Chaos Engineering experiments:

Additional References:
Summary
In this post, I have explained the concept of Chaos Engineering and compared alternatives to cloud-managed services.
Using Chaos Engineering as part of a regular development process will allow you to increase the resiliency of your applications, by studying the effect of failures and designing recovery processes.
Chaos Engineering can also be used as part of a disaster recovery and business continuity process, by testing the resiliency of your systems.
Additional References
- Chaos engineering (Wikipedia)
- Principles of Chaos Engineering
- Chaos Engineering in the Cloud
- What Chaos Engineering Is (and is not)
- AWS re:Invent 2022 – The evolution of chaos engineering at Netflix (NFX303)
- What is AWS Fault Injection Simulator?
- What is Azure Chaos Studio?
- Public Chaos Engineering Stories / Implementations
Introduction to Day 2 Kubernetes

Over the years, I have shared several blog posts about Kubernetes (What are Containers and Kubernetes, Modern Cloud deployment and usage, Introduction to Container Operating Systems, and more).
Kubernetes became a de-facto standard for running container-based workloads (for both on-premise and the public cloud), but most organizations tend to fail on what is referred to as Day 2 Kubernetes operations.
In this blog post, I will review what it means “Day 2 Kubernetes” and how to prepare your workloads for the challenges of Day 2 operations.
Ready, Set, Go!
In the software lifecycle, or the context of this post, the Kubernetes lifecycle, there are several distinct stages:
Day 0 – Planning and Design
In this stage, we focus on designing our solution (application and underlying infrastructure), understanding business needs, budget, required skills, and more.
For the context of this post, let us assume we have decided to build a cloud-native application, made of containers, deployed on top of Kubernetes.
Day 1 – Configuration and Deployment
In this stage, we focus on deploying our application using the Kubernetes orchestrator and setting up the configurations (number of replicas, public ports, auto-scale settings, and more).
Most organizations taking their first steps deploying applications on Kubernetes are stacked at this stage.
They may have multiple environments (such as Dev, Test, UAT) and perhaps even production workloads, but they are still on Day 1.
Day 2 – Operations
Mature organizations have reached this stage.
This is about ongoing maintenance, observability, and continuous improvement of security aspects of production workloads.
In this blog post, I will dive into “Day 2 Kubernetes”.
Day 2 Kubernetes challenges
Below are the most common Kubernetes challenges:
Observability
Managing Kubernetes at a large scale requires insights into the Kubernetes cluster(s).
It is not enough to monitor the Kubernetes cluster by collecting performance logs, errors, or configuration changes (such as Nodes, Pods, containers, etc.)
We need to have the ability to truly understand the internals of the Kubernetes cluster (from logs, metrics, etc.), be able to diagnose the behavior of the Kubernetes cluster – not just performance issues, but also debug problems, detect anomalies, and (hopefully) be able to anticipate problems before they affect customers.
Prefer to use cloud-native monitoring and observability tools to monitor Kubernetes clusters.
Without proper observability, we will not be able to do root cause analysis and understand problems with our Kubernetes cluster or with our application deployed on top of Kubernetes.
Common tools for observability:
- Prometheus – An open-source systems monitoring and alerting toolkit for monitoring large cloud-native deployments.
- Grafana – An open-source query, visualization, and alerting tool (resource usage, built-in and customized metrics, alerts, dashboards, log correlation, etc.)
- OpenTelemetry – A collection of open-source tools for collecting and exporting telemetry data (metrics, logs, and traces) for analyzing software performance and behavior.
Additional references for managed services:
- Amazon Managed Grafana
- Amazon Managed Service for Prometheus
- AWS Distro for OpenTelemetry
- Azure Monitor managed service for Prometheus (Still in preview on April 2023)
- Azure Managed Grafana
- OpenTelemetry with Azure Monitor
- Google Cloud Managed Service for Prometheus
- Google Cloud Logging plugin for Grafana
- OpenTelemetry Collector (Part of Google Cloud operations suite)
Security and Governance
On the one hand, it is easy to deploy a Kubernetes cluster in private mode, meaning, the API server or the Pods are on an internal subnet and not directly exposed to customers.
On the other hand, many challenges in the security domain need to be solved:
- Secrets Management – A central and secure vault for generating, storing, retrieving, rotating, and eventually revoking secrets (instead of hard-coded static credentials inside our code or configuration files).
- Access control mechanisms – Ability to control what persona (either human or service account) has access to which resources inside the Kubernetes cluster and to take what actions, using RBAC (Role-based access control) mechanisms.
- Software vulnerabilities – Any vulnerabilities related to code – from programming languages (such as Java, PHP, .NET, NodeJS, etc.), use of open-source libraries with known vulnerabilities, to vulnerabilities inside Infrastructure-as-Code (such as Terraform modules)
- Hardening – Ability to deploy a Kubernetes cluster at scale, using secured configuration, such as CIS Benchmarks.
- Networking – Ability to set isolation between different Kubernetes clusters or even between different development teams using the same cluster, not to mention multi-tenancy where using the same Kubernetes platform to serve different customers.
Additional Reference:
- Securing the Software Supply Chain in the Cloud
- OPA (Open Policy Agent) Gatekeeper
- Kyverno – Kubernetes Native Policy Management
- Foundational Cloud Security with CIS Benchmarks
- Amazon EKS Best Practices Guide for Security
- Azure security baseline for Azure Kubernetes Service (AKS)
- GKE Security Overview
Developers experience
Mature organizations have already embraced DevOps methodologies for pushing code through a CI/CD pipeline.
The entire process needs to be done automatically and without direct access of developers to production environments (for this purpose you build break-glass mechanisms for the SRE teams).
The switch to applications wrapped inside containers, allowed developers to develop locally or in the cloud and push new versions of their code to various environments (such as Dev, Test, and Prod).
Integration of CI/CD pipeline, together with containers, allows organizations to continuously develop new software versions, but it requires expanding the knowledge of developers using training.
The use of GitOps and tools such as Argo CD allowed a continuous delivery process for Kubernetes environments.
To allow developers, the best experience, you need to integrate the CI/CD process into the development environment, allowing the development team the same experience as developing any other application, as they used to do in the on-premise for legacy applications, which can speed the developer onboarding process.
Additional References:
- GitOps 101: What is it all about?
- Argo CD – Declarative GitOps CD for Kubernetes
- Continuous Deployment and GitOps delivery with Amazon EKS Blueprints and ArgoCD
- Getting started with GitOps, Argo, and Azure Kubernetes Service
- Building a Fleet of GKE clusters with ArgoCD
Storage
Any Kubernetes cluster requires persistent storage – whether organizations choose to begin with an on-premise Kubernetes cluster and migrate to the public cloud, or provision a Kubernetes cluster using a managed service in the cloud.
Kubernetes supports multiple types of persistent storage – from object storage (such as Azure Blob storage or Google Cloud Storage), block storage (such as Amazon EBS, Azure Disk, or Google Persistent Disk), or file sharing storage (such as Amazon EFS, Azure Files or Google Cloud Filestore).
The fact that each cloud provider has its implementation of persistent storage adds to the complexity of storage management, not to mention a scenario where an organization is provisioning Kubernetes clusters over several cloud providers.
To succeed in managing Kubernetes clusters over a long period, knowing which storage type to use for each scenario, requires storage expertise.
High Availability
High availability is a common requirement for any production workload.
The fact that we need to maintain multiple Kubernetes clusters (for example one cluster per environment such as Dev, Test, and Prod) and sometimes on top of multiple cloud providers, make things challenging.
We need to design in advance where to provision our cluster(s), thinking about constraints such as multiple availability zones, and sometimes thinking about how to provision multiple Kubernetes clusters in different regions, while keeping HA requirements, configurations, secrets management, and more.
Designing and maintaining HA in Kubernetes clusters requires a deep understanding of Kubernetes internals, combined with knowledge about specific cloud providers’ Kubernetes management plane.
Additional References:
- Designing Production Workloads in the Cloud
- Amazon EKS Best Practices Guide for Reliability
- AKS – High availability Kubernetes cluster pattern
- GKE best practices: Designing and building highly available clusters
Cost optimization
Cost is an important factor in managing environments in the cloud.
It can be very challenging to design and maintain multiple Kubernetes clusters while trying to optimize costs.
To monitor cost, we need to deploy cost management tools (either the basic services provided by the cloud provider) or third-party dedicated cost management tools.
For each Kubernetes cluster, we need to decide on node instance size (amount of CPU/Memory), and over time, we need to review the node utilization and try to right-size the instance type.
For non-production clusters (such as Dev or Test), we need to understand from the cloud vendor documentation, what are our options to scale the cluster size to the minimum, when not in use, and be able to spin it back up, when required.
Each cloud provider has its pricing options for provisioning Kubernetes clusters – for example, we might want to choose reserved instances or saving plans for production clusters that will be running 24/7, while for temporary Dev or Test environment, we might want to choose Spot instances and save cost.
Additional References:
- Cost optimization for Kubernetes on AWS
- Azure Kubernetes Service (AKS) – Cost Optimization Techniques
- Best practices for running cost-optimized Kubernetes applications on GKE
- 5 steps to bringing Kubernetes costs in line
- 4 Strategies for Kubernetes Cost Reduction
Knowledge gap
Running Kubernetes clusters requires a lot of knowledge.
From the design, provision, and maintenance, usually done by DevOps or experienced cloud engineers, to the deployment of new applications, usually done by development teams.
It is crucial to invest in employee training, in all aspects of Kubernetes.
Constant updates using vendor documentation, online courses, blog posts, meetups, and technical conferences will enable teams to gain the knowledge required to keep up with Kubernetes updates and changes.
Additional References:
- Kubernetes Blog
- AWS Containers Blog
- Azure Kubernetes Service (AKS) issue and feature tracking
- Google Cloud Blog – Containers & Kubernetes
Third-party integration
Kubernetes solve part of the problems related to container orchestration.
As an open-source solution, it can integrate with other open-source complimentary solutions (from monitoring, security and governance, cost management, and more).
Every organization might wish to use a different set of tools to achieve each task relating to the ongoing maintenance of the Kubernetes cluster or for application deployment.
Selecting the right tools can be challenging as well, due to various business or technological requirements.
It is recommended to evaluate and select Kubernetes native tools to achieve the previously mentioned tasks or resolve the mentioned challenges.
Summary
In this blog post, I have reviewed the most common Day 2 Kubernetes challenges.
I cannot stress enough the importance of employee training in deploying and maintaining Kubernetes clusters.
It is highly recommended to evaluate and look for a centralized management platform for deploying, monitoring (using cloud-native tools), and securing the entire fleet of Kubernetes clusters in the organization.
Another important recommendation is to invest in automation – from policy enforcement to application deployment and upgrade, as part of the CI/CD pipeline.
I recommend you continue learning and expanding your knowledge in the ongoing changed world of Kubernetes.
Introduction to deep learning hardware in the cloud
For more than a decade, organizations are using machine learning for various use cases such as predictions, assistance in the decision-making process, and more.
Due to the demand for high computational resources and in many cases expensive hardware requirements, the public cloud became one of the better ways for running machine learning or deep learning processes.
Terminology
Before we dive into the topic of this post, let us begin with some terminology:
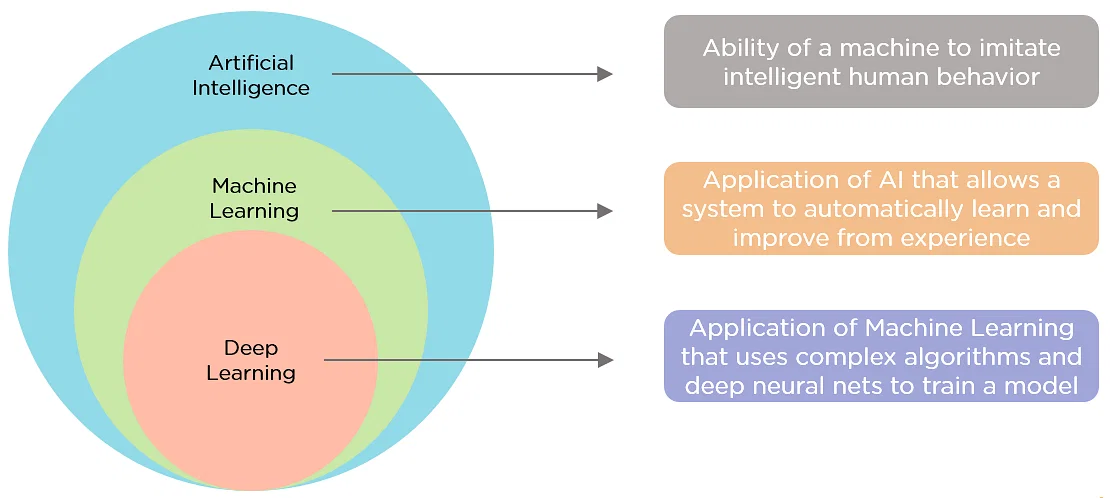
- Artificial Intelligence – “The ability of a computer program or a machine to think and learn”, Wikipedia
- Machine Learning – “The task of making computers more intelligent without explicitly teaching them how to behave”, Bill Brock, VP of Engineering at Very
- Deep Learning – “A branch of machine learning that uses neural networks with many layers. A deep neural network analyzes data with learned representations like the way a person would look at a problem”, Bill Brock, VP of Engineering at Very
Public use cases of deep learning
- Disney makes its archive accessible using deep learning built on AWS
- NBA accelerates modern app time to market to ramp up fans’ excitement
- Satair: Enhancing customer service with Lilly, a smart online assistant built on Google Cloud
In this blog post, I will focus on deep learning and hardware available in the cloud for achieving deep learning.
Deep Learning workflow
The deep learning process is made of the following steps:
- Prepare – Store data in a repository (such as object storage or a database)
- Build – Choose a machine learning framework (such as TensorFlow, PyTorch, Apache MXNet, etc.)
- Train – Choose hardware (compute, network, storage) to train the model you have built (“learn” and optimize model from data)
- Inference – Using the trained model (on large scale) to make a prediction
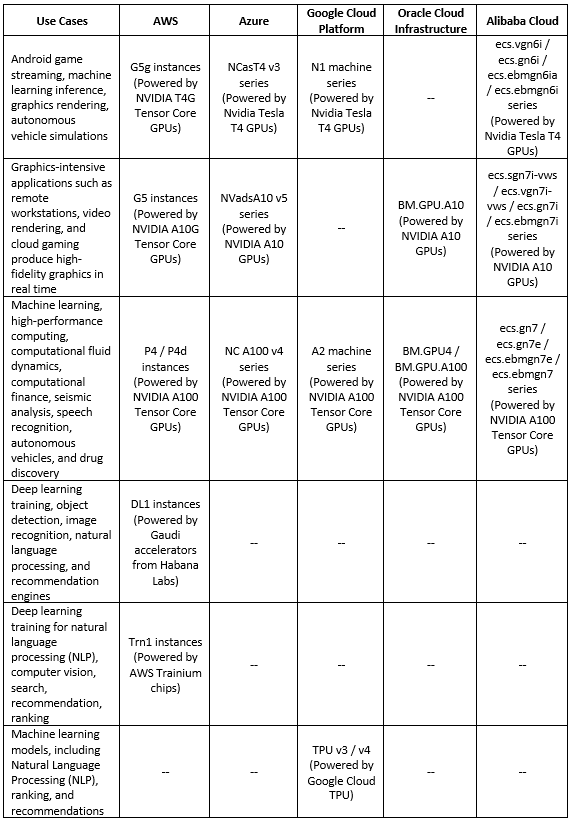
Deep Learning processors comparison (Training phase)
Below is a comparison table for the various processors available in the public cloud, dedicated to the deep learning training phase:
Additional References
- Amazon EC2 – Accelerated Computing
- AWS EC2 Instances Powered by Gaudi Accelerators for Training Deep Learning Models
- AWS Trainium
- Azure – GPU-optimized virtual machine sizes
- Google Cloud – GPU platforms
- Google Cloud – Introduction to Cloud TPU
- Oracle Cloud Infrastructure – Compute Shapes – GPU Shapes
- Alibaba Cloud GPU-accelerated compute-optimized and vGPU-accelerated instance families
- NVIDIA T4 Tensor Core GPU
- NVIDIA A10 Tensor Core GPU
- NVIDIA A100 Tensor Core GPU
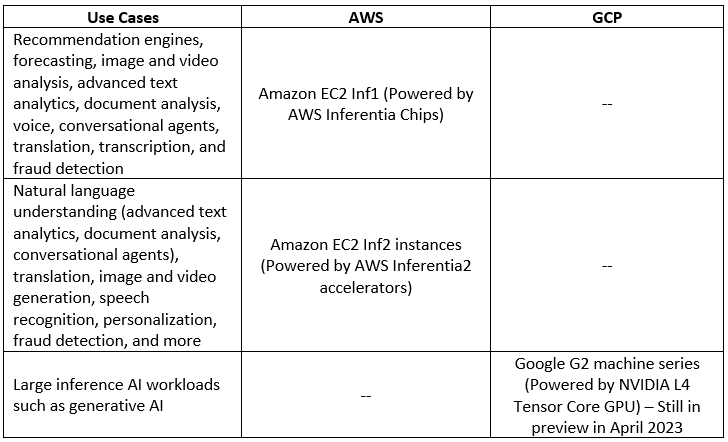
Deep Learning processors comparison (Inference phase)
Below is a comparison table for the various processors available in the public cloud, dedicated to the deep learning inference phase:
Additional References
Summary
In this blog post, I have shared information about the various alternatives for using hardware available in the public cloud to run deep learning processes.
I recommend you to keep reading and expand your knowledge on both machine learning and deep learning, what services are available in the cloud and what are the use cases to achieve outcomes from deep learning.
Additional References
- AWS Machine Learning Infrastructure
- AWS – Select the right ML instance for your training and inference jobs
- AWS – Accelerate deep learning and innovate faster with AWS Trainium
- Azure AI Infrastructure
- Google Cloud Platform – AI Infrastructure
- Oracle Cloud – Machine Learning Services
- Alibaba Cloud – Machine Learning Platform for AI
Managing network security aspects in the public cloud

Managing cloud environments on large scale has many challenges.
One of the challenges many organizations are facing is managing network inbound/outbound network connectivity to their cloud environments.
Due to the nature of the public cloud, all resources are potentially public, unless we configured them otherwise.
What are the challenges in the network security domain?
There are many challenges related to network security, here are the most common ones:
- Unauthorized inbound network access – Publicly facing resources (such as virtual machines, object storage, databases, etc.) allowing anyone on the Internet access to the resources
- Unrestricted outbound network access – Internal resources (such as virtual machines, databases, serverless, etc.) can initiate outbound traffic to resources on the public Internet
- Managing network access rules at large scale – Ability to control thousands of firewall rules created over time, while managing multiple accounts for a specific cloud provider (or even multiple different cloud providers)
- Understanding the network attack surface – Ability to get a clear view of what inbound or outbound traffic is allowed or denied in a large cloud environment with multiple accounts
- Enabling the business, while keeping the infrastructure secure – Ability to respond to multiple business requests, using small network/information security / IT team
With all the above challenges, how do we keep our cloud network infrastructure secure and at a large scale?
Set Guardrails
One of the common ways to configure guardrails is to use organizational policies using Policy-as-Code.
All major cloud providers support this capability.
It allows us to configure rules for the maximum allowed permissions over our cloud environments according to our company security policy while allowing developers / DevOps to continue provisioning resources.
AWS Service control policies (SCPs)
Below are sample service control policies that can be configured at the AWS organizational level (with inheritance to the underlining OU’s), for restricting inbound access:
- Detect whether any Amazon EC2 instance has an associated public IPv4 address
- Detect whether Amazon S3 settings to block public access are set as true for the account
- Detects whether an Amazon EKS endpoint is blocked from public access
- Detect whether the AWS Lambda function policy attached to the Lambda resource blocks public access
- Detect whether any Amazon VPC subnets are assigned a public IP address
Azure Policy
Below are sample Azure policies that can be configured at the Azure subscription level, for restricting inbound access:
- Container Apps should disable external network access
- Network interfaces should not have public IPs
- All network ports should be restricted on network security groups associated to your virtual machine
- Function apps should disable public network access
- Azure SQL Managed Instances should disable public network access
- Public network access on Azure SQL Database should be disabled
- Public network access should be disabled for MySQL servers
- Public network access should be disabled for PostgreSQL servers
- Storage accounts should disable public network access
Google Organization Policies
Below are sample Google organization policies that can be configured at the GCP Project level, for restricting inbound access:
- Restrict public IP access on Cloud SQL instances
- Enforce Public Access Prevention
- Disable VM serial port access
- Define allowed external IPs for VM instances
Controlling inbound/outbound network traffic at scale
At large scale, we cannot rely on the built-in layer 4 access control mechanisms (such as AWS Security groups, Azure Network Security Groups, or GCP Firewall Rules) to define inbound or outbound traffic from/to our cloud environments.
For large scale, we should consider alternatives that will allow us to configure network restrictions, while allowing us central visibility over our entire cloud environment.
Another aspect we should keep in mind is that the default layer 4 access control mechanisms do provide us advanced protection against today’s threats, such as the ability to perform TLS inspection, control web traffic using URL filtering, etc.
Cloud-native firewall services:

Note: If you prefer to use 3rd party NGFW, you can deploy it using AWS Gateway Load Balancer or Azure Gateway Load Balancer.
Additional references
Understanding the network attack surface
One of the common issues with large cloud environments is to have a visibility of which inbound or outbound ports are opened to the Internet, exposing the cloud environment.
Common services to allow network visibility:
Another alternative for getting insights into attack surface or network misconfiguration is to deploy 3rd party Cloud Security Posture Management (CSPM) solution, which will allow you central visibility into publicly accessible virtual machines, databases, object storage, and more, over multiple cloud providers’ environments.
Summary
In this blog post, I have presented common challenges in managing network security aspects in cloud environments.
Using a combination of organizational policies, strict inbound/outbound traffic control, and good visibility over large or complex cloud environments, it is possible to enable the business to move forward, while mitigating security risks.
As the cloud threat landscape evolves, so do security teams need to research for suitable solutions to enable the business, while keeping the cloud environments secure.
Distributed Managed PostgreSQL Database Alternatives in the Cloud
In 2020 I have published a blog post called Running MySQL Managed Database in the Cloud, comparing different alternatives for running MySQL database in the cloud.
In this blog post, I will take one step further, comparing PostgreSQL database alternatives deployed on a distributed system.
Background
PostgreSQL is an open-source relational database, used by many companies, and is very common among cloud applications, where companies prefer an open-source solution, supported by a strong community, as an alternative to commercial database engines.
The simplest way to run the PostgreSQL engine in the cloud is to choose one of the managed database services, such as Amazon RDS for PostgreSQL or Google Cloud SQL for PostgreSQL, and allow you to receive a fully managed database.
In this scenario, you as the customer, receive a fully managed PostgreSQL database cluster, that spans across multiple availability zones, and the cloud provider is responsible for maintaining the underlining operating system, including patching, hardening, monitoring, and backup (up to the service limits).
As a customer, you receive an endpoint (i.e., DNS name and port), configure access controls (such as AWS Security groups or GCP VCP Firewall rules), and set authentication and authorization for what identities have access to the managed database.
This solution is suitable for most common use cases if your applications (and perhaps customers) are in a specific region.
What happens in a scenario where you would like to design a truly highly available architecture span across multiple regions (in the rare case of an outage in a specific region) and serve customers across the globe, deploying your application close to your customers?
The solution for allowing high availability and multi-region deployment is to deploy the PostgreSQL engine in a managed distributed database.
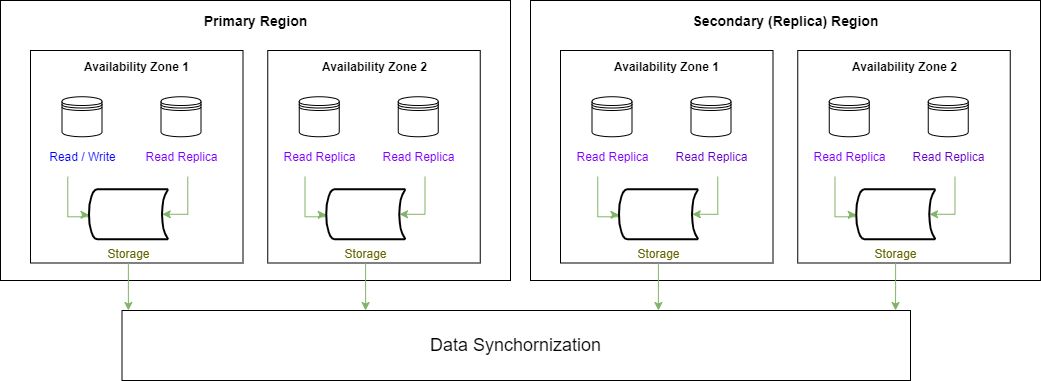
PostgreSQL Distributed Database Alternatives
The distributed system allows you to run a database across multiple regions while keeping the data synchronized.
In a distributed database, the compute layer (i.e., virtual machines) running the database engine is deployed on separate nodes from the storage and logging layer, allowing you to gain the benefits of the cloud provider’s backend infrastructure low-latency replication capabilities.
In each system, there is a primary cluster (which oversees read/write actions) and one or more secondary clusters (read-only replicas).
Architecture diagram:
Let us examine some of the cloud providers’ alternatives:
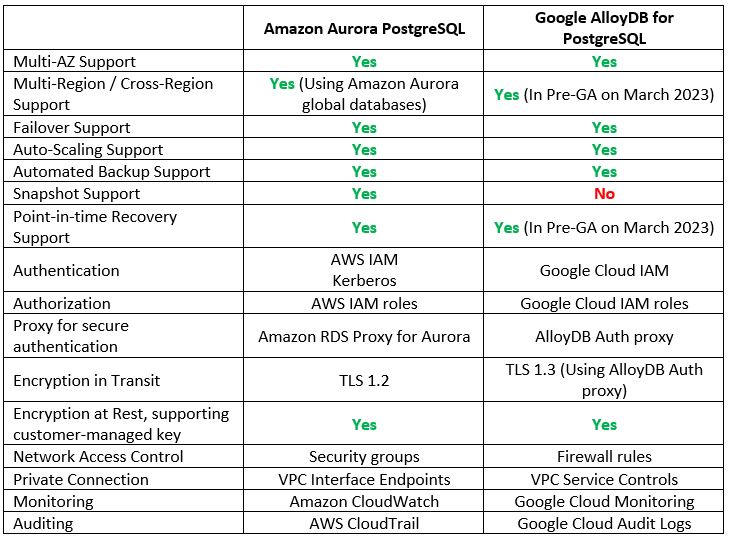
Additional References
Summary
In this blog post, I have compared two alternatives for running PostgreSQL-compatible database in a distributed architecture.
If you are looking for a relational database solution with high durability that will auto-scale according to application load, and with the capability to replicate data across multiple regions, you should consider one of the alternatives I have mentioned in this blog post.
As always, I recommend you to continue reading and expanding your knowledge on the topic and evaluate during the architecture design phase, if your workloads can benefit from a distributed database system.
Additional References
Comparing Confidential Computing Alternatives in the Cloud
In 2020, I have published the blog post “Confidential Computing and the Public Cloud“.
Now, let us return to the subject of confidential computing and see what has changed among cloud providers.
Before we begin our conversation, let us define what is “Confidential Computing”, according to The Confidential Computing Consortium:
“Confidential Computing is the protection of data in use by performing the computation in a hardware-based, attested Trusted Execution Environment“
Source: https://confidentialcomputing.io/about
Introduction
When we store data in the cloud, there are various use cases where we would like to protect data from unauthorized access (from an external attacker to an internal employee and up to a cloud provider engineer who potentially might have access to customers’ data).
To name a few examples of data who would like to protect – financial data (such as credit card information), healthcare data (PHI – Personal Health Information), private data about a persona (PII – Personally Identifiable Information), government data, military data, and more.
When we would like to protect data in the cloud, we usually encrypt it in transit (with protocols such as TLS) and at rest (with algorithms such as AES).
At some point in time, either an end-user or a service needs access to the encryption keys and the data is decrypted in the memory of the running machine.
Confidential computing comes to solve the problem, by encrypting data while in use, and this is done using a hardware-based Trusted Execution Environment (TEE), also known as the hardware root of trust.
The idea behind it is to decrease the reliance on proprietary software and provide security at the hardware level.
To validate that data is protected and has not been tampered with, confidential computing performs a cryptographic process called attestation, which allows the customer to audit and make sure data was not tempered by any unauthorized party.
There are two approaches to achieving confidential computing using hardware-based TEEs:
- Application SDKs – The developer is responsible for data partitioning and encryption. Might be influenced by programming language and specific hardware TEEs.
- Runtime deployment systems – Allows the development of cross-TEE portable applications.
As of March 2023, the following are the commonly supported hardware alternatives to achieve confidential computing or encryption in use:
- Intel Software Guard Extensions (Intel SGX)
- AMD Secure Encrypted Virtualization (SEV), based on AMD EPYC processors
AWS took a different approach when they released the AWS Nitro Enclaves technology.
The AWS Nitro System is made from Nitro Cards (to provision and manage compute, memory, and storage), Nitro Security Chip (the link between the CPU and the place where customer workloads run), and the Nitro Hypervisor (receive virtual machine management commands and assign functions to the Nitro hardware interfaces).
Cloud Providers Comparison
All major cloud providers have their implementation and services that support confidential computing.
Below are the most used services supporting confidential computing:
Virtual Machine supported instance types
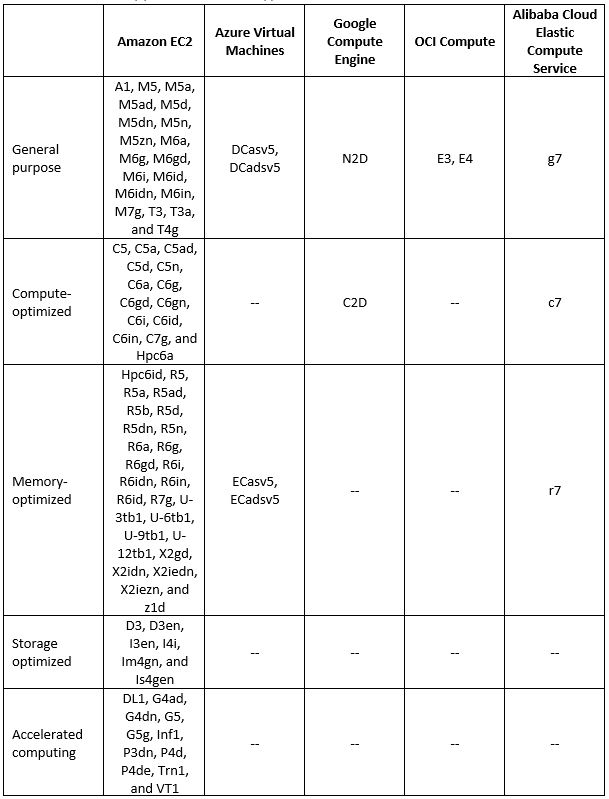
Additional References:
- Instances built on the AWS Nitro System
- Azure Confidential VMs
- Introducing high-performance Confidential Computing with N2D and C2D VMs
- Oracle Cloud Infrastructure Confidential Computing
- Alibaba Cloud – Build a confidential computing environment by using Enclave
Managed Relational Database supported instance types

Additional References:
Managed Containers Services Comparison
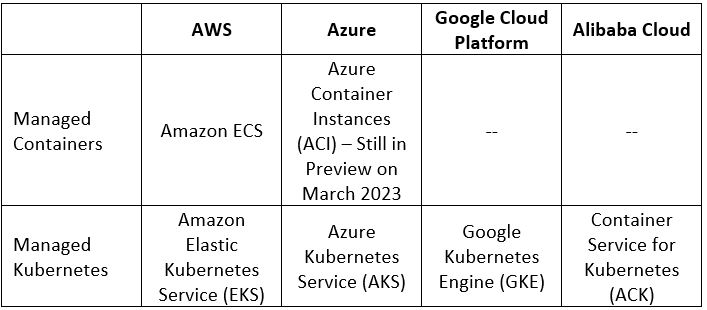
Additional References:
- Using Enclaves with Amazon EKS
- Azure Confidential containers
- Encrypt workload data in use with Confidential Google Kubernetes Engine Nodes
- Alibaba Cloud Container Service for Kubernetes (ACK) clusters supports confidential computing
Managed Hadoop Services supported instance types
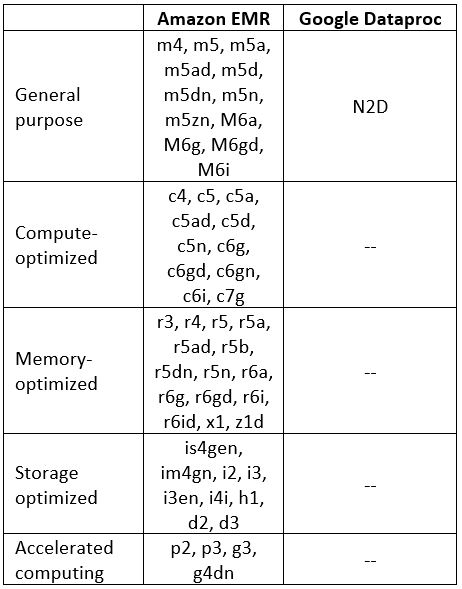
Additional References:
Summary
In this blog post, we have learned what confidential computing means, how it works, and why would we as customers need confidential computing to keep the privacy of our data stored in the public cloud.
We have also compared major cloud providers offering confidential computing-supported services.
The field of confidential computing continues to evolve – both from cloud providers adding more services to support confidential computing and allowing customers to have confidence storing data in the cloud and from third-party security vendors, offering cross-cloud platforms solutions, allowing an easy way to secure data in the cloud.
I encourage everyone to read and expand their knowledge about confidential computing implementations.
Additional References:
Introduction to Cloud Load-Balancers

We have been using load-balancing technology for many years.
What is the purpose of load-balancers and what are the alternatives offered as managed services by the public cloud providers?
Terminology
Below are some important concepts regarding cloud load-balancers:
- Private / Internal Load-Balancer – A load-balancer serving internal traffic (such as traffic from public websites to a back-end database)
- Public / External Load-Balancer – A load-balancer that exposes a public IP and serves external traffic (such as traffic from customers on the public Internet to an external website)
- Regional Load-Balancer – A load-balancer that is limited to a specific region of the cloud provider
- Global Load-Balancer – A load-balancer serving customers from multiple regions around the world using a single public IP
- TLS Termination / Offloading – A process where a load-balancer decrypt encrypted incoming traffic, for further analysis (such as traffic inspection) and either pass the traffic to the back-end nodes decrypted (offloading the encrypted traffic) or pass the traffic encrypted to the back-end nodes
What are the benefits of using load balancers?
Load-balancers offer our applications the following benefits:
- Increased scalability – combined with “auto-scale” we can benefit from the built-in elasticity of cloud services, allowing us to increase or decrease the amount of compute services (such as VMs, containers, and database instances) according to our application’s load
- Redundancy – load-balancers allow us to send traffic to multiple back-end servers (or containers), and in case of a failure in a specific back-end node, the load-balancer will send traffic to other healthy nodes, allowing our service to continue serving customers
- Reduce downtime – consider a scenario where we need to schedule maintenance work (such as software upgrades in a stateful architecture), using a load-balancer, we can remove a single back-end server (or container), drain the incoming traffic, and send new customers’ requests to other back-end nodes, without affecting the service
- Increase performance – assuming our service suffers from a peak in traffic, adding more back-end nodes will allow us a better performance to serve our customers
- Manage failures – one of the key features of a load-balancer is the ability to check the health status of the back-end nodes, and in case one of the nodes does not respond (or function as expected), the load-balancer will not send new traffic to the failed node
Layer 4 Load-Balancers
The most common load-balancers operate at layer 4 of the OSI model (the network/transport layer), and usually, we refer to them as network load-balancers.
The main benefit of a network load balancer is extreme network performance.
Let us compare the cloud providers’ alternatives:
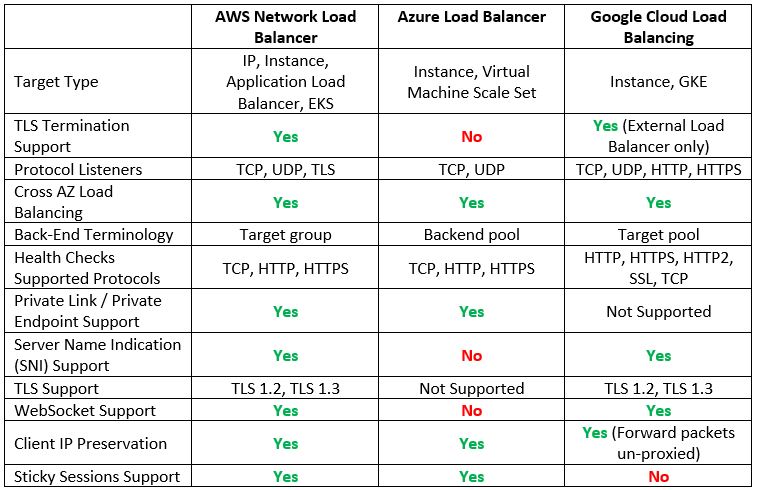
Additional reference
- What is a Network Load Balancer?
https://docs.aws.amazon.com/elasticloadbalancing/latest/network/introduction.html
- What is Azure Load Balancer?
https://learn.microsoft.com/en-us/azure/load-balancer/load-balancer-overview
- Google Cloud Load Balancing overview
https://cloud.google.com/load-balancing/docs/load-balancing-overview
Layer 7 Load-Balancers
When we need to load balance modern applications traffic, we use application load balancers, which operate at layer 7 of the OSI model (the application layer).
Layer 7 load-balancers have an application awareness, meaning you can configure routing rules to route traffic to two different versions of the same application (using the same DNS name), but with different URLs.
Let us compare the cloud providers’ alternatives:
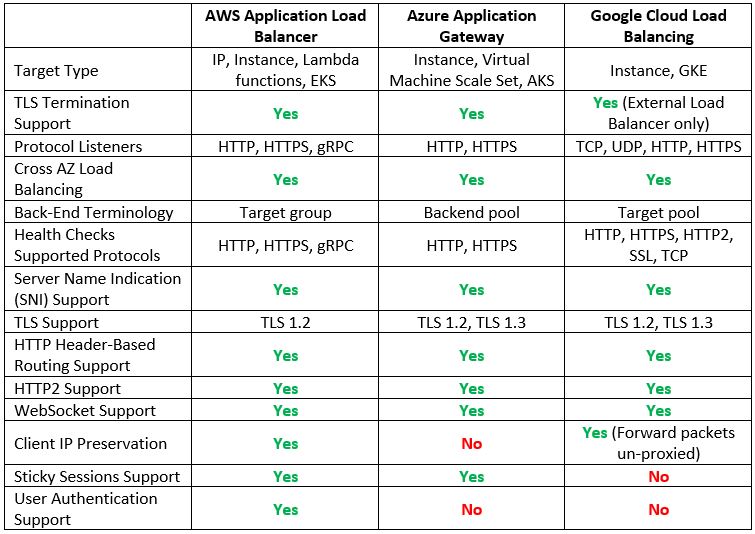
Additional reference
- What is an Application Load Balancer?
https://docs.aws.amazon.com/elasticloadbalancing/latest/application/introduction.html
- What is Azure Application Gateway?
https://learn.microsoft.com/en-us/azure/application-gateway/overview
Global Load-Balancers
Although only Google has a native global load balancer, both AWS and Azure have alternatives, which allow us to configure a multi-region architecture serving customers from multiple regions around the world.
Let us compare the cloud providers’ alternatives:
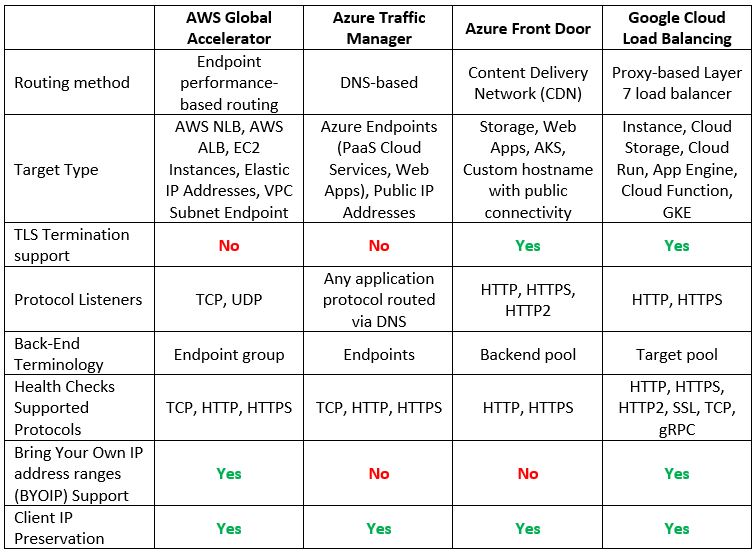
Additional reference
- What is AWS Global Accelerator?
https://docs.aws.amazon.com/global-accelerator/latest/dg/what-is-global-accelerator.html
- What is Traffic Manager?
https://learn.microsoft.com/en-us/azure/traffic-manager/traffic-manager-overview
- What is Azure Front Door?
https://learn.microsoft.com/en-us/azure/frontdoor/front-door-overview
Summary
In this blog post, we have reviewed why we need cloud load balancers when designing scalable and highly available architectures.
We reviewed the different types of managed cloud load balancers and compared the hyper-scale public cloud providers and their various capabilities.
When designing a modern application, considering network aspects (such as internal, external, or even global availability requirements), will allow you better application performance, availability, and customer experience.
Additional references
- AWS Elastic Load Balancing features
https://aws.amazon.com/elasticloadbalancing/features
- Azure Load-balancing options
- Google Cloud Load balancer feature comparison
Designing Production Workloads in the Cloud

Whether we serve internal customers or external customers over the public Internet, we all manage production workloads at some stage in the application lifecycle.
In this blog post, I will review various aspects and recommendations when managing production workloads in the public cloud (although, some of them may be relevant for on-premise as well).
Tip #1 – Think big, plan for large scale
Production workloads are meant to serve many customers simultaneously.
Don’t think about the first 1000 customers who will use your application, plan for millions of concurrent connections from day one.
Take advantage of the cloud elasticity when you plan your application deployment, and use auto-scaling capabilities to build a farm of virtual machines or containers, to be able to automatically scale in or scale out according to application load.
Using event-driven architecture will allow you a better way to handle bottlenecks on specific components of your application (such as high load on front web servers, API gateways, backend data store, etc.)
Tip #2 – Everything breaks, plan for high availability
No business can accept downtime of a production application.
Always plan for the high availability of all components in your architecture.
The cloud makes it easy to design highly-available architectures.
Cloud infrastructure is built from separate geographic regions, and each region has multiple availability zones (which usually means several distinct data centers).
When designing for high availability, deploy services across multiple availability zones, to mitigate the risk of a single AZ going down (together with your production application).
Use auto-scaling services such as AWS Auto Scaling, Azure Autoscale, or Google Autoscale groups.
Tip #3 – Automate everything
The days we used to manually deploy servers and later manually configure each server are over a long time ago.
Embrace the CI/CD process, and build steps to test and provision your workloads, from the infrastructure layer to the application and configuration layer.
Take advantage of Infrastructure-as-Code to deploy your workloads.
Whether you are using a single cloud vendor and putting efforts into learning specific IaC language (such as AWS CloudFormation, Azure Resource Manager, or Google Cloud Deployment Manager), or whether you prefer to learn and use cloud-agnostic IaC language such as Terraform, always think about automation.
Automation will allow you to deploy an entire workload in a matter of minutes, for DR purposes or for provisioning new versions of your application.
Tip #4 – Limit access to production environments
Traditional organizations are still making the mistake of allowing developers access to production, “to fix problems in production”.
As a best practice human access to production workloads must be prohibited.
For provisioning of new services or making changes to existing services in production, we should use CI/CD process, running by a service account, in a non-interactive mode, following the principle of least privilege.
For troubleshooting or emergency purpose, we should create a break-glass process, allowing a dedicated group of DevOps or Service Reliability Engineers (SREs) access to production environments.
All-access attempts must be audited and kept in an audit system (such as SIEM), with read permissions for the SOC team.
Always use secure methods to login to operating systems or containers (such as AWS Systems Manager Session Manager, Azure Bastion, or Google Identity-Aware Proxy)
Enforce the use of multi-factor authentication (MFA) for all human access to production environments.
Tip #5 – Secrets Management
Static credentials of any kind (secrets, passwords, certificates, API keys, SSH keys) are prone to be breached when used over time.
As a best practice, we must avoid storing static credentials or hard-code them in our code, scripts, or configuration files.
All static credentials must be generated, stored, retrieved, rotated, and revoked automatically using a secrets management service.
Access to the secrets management requires proper authentication and authorization process and is naturally audited and logs must be sent to a central logging system.
Use Secrets Management services such as AWS Secrets Manager, Azure Key Vault, or Google Secret Manager.
Tip #6 – Auto-remediation of vulnerabilities
Vulnerabilities can arise for various reasons – from misconfigurations to packages with well-known vulnerabilities to malware.
We need to take advantage of cloud services and configure automation to handle the following:
- Vulnerability management – Run vulnerability scanners on regular basis to automatically detect misconfigurations or deviations from configuration standards (services such as Amazon Inspector, Microsoft Defender, or Google Security Command Center).
- Patch management – Create automated processes to check for missing OS patches and use CI/CD processes to push security patches (services such as AWS Systems Manager Patch Manager, Azure Automation Update Management, or Google OS patch management).
- Software composition analysis (SCA) – Run SCA tools as part of the CI/CD process to automatically detect open-source libraries/packages with well-known vulnerabilities (services such as Amazon Inspector for ECR, Microsoft Defender for Containers, or Google Container Analysis).
- Malware – If your workload contains virtual machines, deploy anti-malware software at the operating system level, to detect and automatically block malware.
- Secure code analysis – Run SAST / DAST tools as part of the CI/CD process, to detect vulnerabilities in your code (if you cannot auto-remediate, at least break the build process).
Tip #7 – Monitoring and observability
Everything will eventually fail.
Log everything – from system health, performance logs, and application logs to user experience logs.
Monitor the entire service activity (from the operating system, network, application, and every part of your workload).
Use automated services to detect outages or service degradation and alert you in advance, before your customers complain.
Use services such as Amazon CloudWatch, Azure Monitor, or Google Cloud Logging.
Tip #8 – Minimize deviations between Dev, Test, and Production environments
Many organizations still believe in the false sense that lower environments (Dev, Test, QA, UAT) can be different from production, and “we will make all necessary changes before moving to production”.
If you build your environments differently, you will never be able to test changes or new versions of your applications/workloads in a satisfying manner.
Use the same hardware (from instance type, amount of memory, CPU, and storage type) when provisioning compute services.
Provision resources to multiple AZs, in the same way, as provision for production workloads.
Use the same Infrastructure-as-Code to provision all environments, with minor changes such as tagging indicating dev/test/prod, different CIDRs, and different endpoints (such as object storage, databases, API gateway, etc.)
Some managed services (such as API gateways, WAF, DDoS protection, and more), has different pricing tiers (from free, standard to premium), allowing you to consume different capabilities or features – conduct a cost-benefit analysis and consider the risk of having different pricing tiers for Dev/Test vs. Production environments.
Summary
Designing production workloads have many aspects to consider.
We must remember that production applications are our face to our customers, and as such, we would like to offer highly-available and secured production applications.
This blog post contains only part of the knowledge required to design, deploy, and operate production workloads.
I highly recommend taking the time to read vendor documentation, specifically the well-architected framework documents – they contain information gathered by architects, using experience gathered over years from many customers around the world.
Additional references
- AWS Well-Architected Framework
https://docs.aws.amazon.com/wellarchitected/latest/framework/welcome.html
- Microsoft Azure Well-Architected Framework
https://learn.microsoft.com/en-us/azure/architecture/framework
- Google Cloud Architecture Framework